《趣学算法》——第二章(贪心算法)
第二章 贪心算法
从前,有一个很穷的人救了一条蛇的命,蛇为了报答他的救命之恩,于是就让这个人提出要求,满足他的愿望。这个人一开始只要求简单的衣食,蛇都满足了他的愿望,后来慢慢的贪欲生起,要求做官,蛇也满足了他。这个人直到做了宰相还不满足,还要求做皇帝。蛇此时终于明白了,人的贪心是永无止境的,于是一口就把这个人吞掉了。
所以,蛇吞掉的是宰相,而不是大象。故此,留下了“人心不足蛇吞相”的典故。
2.1 人之初,性本贪
我们小时候背诵《三字经》,“人之初,性本善,性相近,习相远。”其实我觉得很多时候“人之初,性本贪”。小孩子吃糖果,总是想要多多的;吃水果,想要最大的;买玩具,总是想要最好的,这些东西并不是大人教的,而是与生俱来的。对美好事物的趋优性,就像植物的趋光性,“良禽择木而栖,贤臣择主而事”“窈窕淑女,君子好逑”,我们似乎永远在追求美而优的东西。现实中的很多事情,正是因为趋优性使我们的生活一步一步走向美好。例如,我们竭尽所能买了一套房子,然后就想要添置一些新的家具,再就想着可能还需要一辆车子……
凡事都有两面性,一把刀可以做出美味佳肴,也可以变成杀人凶器。在这里,我们只谈好的“贪心”。
2.1.1 贪心本质
一个贪心算法总是做出当前最好的选择,也就是说,它期望通过局部最优选择从而得到全局最优的解决方案。
——《算法导论》
我们经常会听到这些话:“人要活在当下”“看清楚眼前”……贪心算法正是“活在当下,看清楚眼前”的办法,从问题的初始解开始,一步一歩地做出当前最好的选择,逐步逼近问题的目标,尽可能地得到最优解,即使达不到最优解,也可以得到最优解的近似解。
贪心算法在解决问题的策略上“目光短浅”,只根据当前已有的信息就做出选择,而且一旦做出了选择,不管将来有什么结果,这个选择都不会改变。换言之,贪心算法并不是从整体最优考虑,它所做出的选择只是在某种意义上的局部最优。贪心算法能得到许多问题的整体最优解或整体最优解的近似解。因此,贪心算法在实际中得到大量的应用。
在贪心算法中,我们需要注意以下几个问题。
(1)没有后悔药。一旦做出选择,不可以反悔。
(2)有可能得到的不是最优解,而是最优解的近似解。
(3)选择什么样的贪心策略,直接决定算法的好坏。
那么,贪心算法需要遵循什么样的原则呢?
2.1.2 贪亦有道
“君子爱财,取之有道”,我们在贪心算法中“贪亦有道”。通常我们在遇到具体问题时,往往分不清哪些问题该用贪心策略求解,哪些问题不能使用贪心策略。经过实践我们发现,利用贪心算法求解的问题往往具有两个重要的特性:贪心选择性质和最优子结构性质。如果满足这两个性质就可以使用贪心算法了。
(1)贪心选择
所谓贪心选择性质是指原问题的整体最优解可以通过一系列局部最优的选择得到。应用同一规则,将原问题变为一个相似的但规模更小的子问题,而后的每一步都是当前最佳的选择。这种选择依赖于已做出的选择,但不依赖于未做出的选择。运用贪心策略解决的问题在程序的运行过程中无回溯过程。关于贪心选择性质,读者可在后续的贪心策略状态空间图中得到深刻的体会。
(2)最优子结构
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的最优子结构性质是该问题是否可用贪心算法求解的关键。例如原问题S={a1,a2,…,ai,…,an},通过贪心选择选出一个当前最优解{ai}之后,转化为求解子问题S−{ai},如果原问题的最优解包含子问题的最优解,则说明该问题满足最优子结构性质,如图2-1所示。
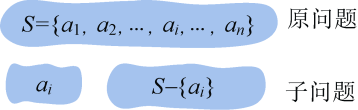
2.1.3 贪心算法秘籍
武林中有武功秘籍,算法中也有贪心秘籍。上面我们已经知道了具有贪心选择和最优子结构性质就可以使用贪心算法,那么如何使用呢?下面介绍贪心算法秘籍。
(1)贪心策略
首先要确定贪心策略,选择当前看上去最好的一个方案。例如,挑选苹果,如果你认为个大的是最好的,那你每次都从苹果堆中拿一个最大的,作为局部最优解,贪心策略就是选择当前最大的苹果;如果你认为最红的苹果是最好的,那你每次都从苹果堆中拿一个最红的,贪心策略就是选择当前最红的苹果。因此根据求解目标不同,贪心策略也会不同。
(2)局部最优解
根据贪心策略,一步一步地得到局部最优解。例如,第一次选一个最大的苹果放起来,记为a1,第二次再从剩下的苹果堆中选择一个最大的苹果放起来,记为a2,以此类推。
(3)全局最优解
把所有的局部最优解合成为原来问题的一个最优解(a1,a2,…)。
怎么有点儿像冒泡排序啊?
“不是六郎似荷花,而是荷花似六郎”!不是贪心算法像冒泡排序,而是冒泡排序使用了贪心算法,它的贪心策略就是每一次从剩下的序列中选一个最大的数,把这些选出来的数放在一起,就得到了从大到小的排序结果,如图2-2所示。
2.2 加勒比海盗船——最优装载问题
在北美洲东南部,有一片神秘的海域,那里碧海蓝天、阳光明媚,这正是传说中海盗最活跃的加勒比海(Caribbean Sea)。17世纪时,这里更是欧洲大陆的商旅舰队到达美洲的必经之地,所以当时的海盗活动非常猖獗,海盗不仅攻击过往商人,甚至攻击英国皇家舰……
有一天,海盗们截获了一艘装满各种各样古董的货船,每一件古董都价值连城,一旦打碎就失去了它的价值。虽然海盗船足够大,但载重量为C,每件古董的重量为wi,海盗们该如何把尽可能多数量的宝贝装上海盗船呢?

2.2.1 问题分析
根据问题描述可知这是一个可以用贪心算法求解的最优装载问题,要求装载的物品的数量尽可能多,而船的容量是固定的,那么优先把重量小的物品放进去,在容量固定的情况下,装的物品最多。采用重量最轻者先装的贪心选择策略,从局部最优达到全局最优,从而产生最优装载问题的最优解。
2.2.2 算法设计
(1)当载重量为定值c时,wi越小时,可装载的古董数量n越大。只要依次选择最小重量古董,直到不能再装为止。
(2)把n个古董的重量从小到大(非递减)排序,然后根据贪心策略尽可能多地选出前i个古董,直到不能继续装为止,此时达到最优。
2.2.3 完美图解
我们现在假设这批古董如图2-4所示。

每个古董的重量如表2-1所示,海盗船的载重量c为30,那么在不能打碎古董又不超过载重的情况下,怎么装入最多的古董?
| 重量w[i] | 4 | 10 | 7 | 11 | 3 | 5 | 14 | 2 || :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- |
(1)因为贪心策略是每次选择重量最小的古董装入海盗船,因此可以按照古董重量非递减排序,排序后如表2-2所示。
| 重量w[i] | 2 | 3 | 4 | 5 | 7 | 10 | 11 | 14 || :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- |
(2)按照贪心策略,每次选择重量最小的古董放入(tmp 代表古董的重量,ans 代表已装裁的古董个数)。
i=0,选择排序后的第1个,装入重量tmp=2,不超过载重量30,ans =1。
i=1,选择排序后的第2个,装入重量tmp=2+3=5,不超过载重量30,ans =2。
i=2,选择排序后的第3个,装入重量tmp=5+4=9,不超过载重量30,ans =3。
i=3,选择排序后的第4个,装入重量tmp=9+5=14,不超过载重量30,ans =4。
i=4,选择排序后的第5个,装入重量tmp=14+7=21,不超过载重量30,ans =5。
i=5,选择排序后的第6个,装入重量tmp=21+10=31,超过载重量30,算法结束。
即放入古董的个数为ans=5个。
2.2.4 伪代码详解
(1)数据结构定义
根据算法设计描述,我们用一维数组存储古董的重量:
1 | double w[N]; //一维数组存储古董的重量 |
(2)按重量排序
可以利用C++中的排序函数sort(见附录B),对古董的重量进行从小到大(非递减)排序。要使用此函数需引入头文件:
1 |
语法描述为:
1 | sort(begin, end)//参数begin和end表示一个范围,分别为待排序数组的首地址和尾地址 |
在本例中只需要调用sort函数对古董的重量进行从小到大排序:
1 | sort(w, w+n); //按古董重量升序排序 |
(3)按照贪心策略找最优解
首先用变量ans记录已经装载的古董个数,tmp代表装载到船上的古董的重量,两个变量都初始化为0。然后按照重量从小到大排序,依次检查每个古董,tmp加上该古董的重量,如果小于等于载重量c,则令ans ++;否则,退出。
1 | int tmp = 0,ans = 0; //tmp代表装载到船上的古董的重量,ans记录已经装载的古董个数 |
2.2.5 实战演练
1 | //program 2-1 |
算法实现和测试
(1)运行环境
Code::Blocks
(2)输入
1 | 请输入载重量c及古董个数n: |
(3)输出
1 | 能装入的古董最大数量为Ans=5 |
2.2.6 算法解析及优化拓展
1.算法复杂度分析
(1)时间复杂度:首先需要按古董重量排序,调用sort函数,其平均时间复杂度为O(nlogn),输入和贪心策略求解的两个for语句时间复杂度均为O(n),因此时间复杂度为O(n + nlog(n))。
(2)空间复杂度:程序中变量tmp、ans等占用了一些辅助空间,这些辅助空间都是常数阶的,因此空间复杂度为O(1)。
2.优化拓展
(1)这一个问题为什么在没有装满的情况下,仍然是最优解?算法要求装入最多数量,假如c为5,4个物品重量分别为1、3、5、7。排序后,可以装入1和3,最多装入两个。分析发现是最优的,如果装大的物品,最多装一个或者装不下,所以选最小的先装才能装入最多的数量,得到解是最优的。
(2)在伪代码详解的第3步“按照贪心策略找最优解”,如果把代码替换成下面代码,有什么不同?
首先用变量ans记录已经装载的古董个数,初始化为n;tmp代表装载到船上的古董的重量,初始化为0。然后按照重量从小到大排序,依次检查每个古董,tmp加上该古董的重量,如果tmp大于等于载重量c,则判断是否正好等于载重量c,并令ans=i+1;否则ans = i,退出。如果tmp小于载重量c,i++,继续下一个循环。
1 | int tmp = 0,ans = n; //ans记录已经装载的古董个数,tmp代表装载到船上的古董的重量 |
(3)如果想知道装入了哪些古董,需要添加什么程序来实现呢?请大家动手试一试吧!
那么,还有没有更好的算法来解决这个问题呢?
2.3 阿里巴巴与四十大盗——背包问题
有一天,阿里巴巴赶着一头毛驴上山砍柴。砍好柴准备下山时,远处突然出现一股烟尘,弥漫着直向上空飞扬,朝他这儿卷过来,而且越来越近。靠近以后,他才看清原来是一支马队,他们共有四十人,一个个年轻力壮、行动敏捷。一个首领模样的人背负沉重的鞍袋,从丛林中一直来到那个大石头跟前,喃喃地说道:“芝麻,开门吧!”随着那个头目的喊声,大石头前突然出现一道宽阔的门路,于是强盗们鱼贯而入。阿里巴巴待在树上观察他们,直到他们走得无影无踪之后,才从树上下来。他大声喊道:“芝麻,开门吧!”他的喊声刚落,洞门立刻打开了。他小心翼翼地走了进去,一下子惊呆了,洞中堆满了财物,还有多得无法计数的金银珠宝,有的散堆在地上,有的盛在皮袋中。突然看见这么多的金银财富,阿里巴巴深信这肯定是一个强盗们数代经营、掠夺所积累起来的宝窟。为了让乡亲们开开眼界,见识一下这些宝物,他想一种宝物只拿一个,如果太重就用锤子凿开,但毛驴的运载能力是有限的,怎么才能用驴子运走最大价值的财宝分给穷人呢?
阿里巴巴陷入沉思中……

2.3.1 问题分析
假设山洞中有n种宝物,每种宝物有一定重量w和相应的价值v,毛驴运载能力有限,只能运走m重量的宝物,一种宝物只能拿一样,宝物可以分割。那么怎么才能使毛驴运走宝物的价值最大呢?
我们可以尝试贪心策略:
(1)每次挑选价值最大的宝物装入背包,得到的结果是否最优?
(2)每次挑选重量最小的宝物装入,能否得到最优解?
(3)每次选取单位重量价值最大的宝物,能否使价值最高?
思考一下,如果选价值最大的宝物,但重量非常大,也是不行的,因为运载能力是有限的,所以第1种策略舍弃;如果选重量最小的物品装入,那么其价值不一定高,所以不能在总重限制的情况下保证价值最大,第2种策略舍弃;而第3种是每次选取单位重量价值最大的宝物,也就是说每次选择性价比(价值/重量)最高的宝物,如果可以达到运载重量m,那么一定能得到价值最大。
因此采用第3种贪心策略,每次从剩下的宝物中选择性价比最高的宝物。
2.3.2 算法设计
(1)数据结构及初始化。将n种宝物的重量和价值存储在结构体three(包含重量、价值、性价比3个成员)中,同时求出每种宝物的性价比也存储在对应的结构体three中,将其按照性价比从高到低排序。采用sum来存储毛驴能够运走的最大价值,初始化为0。
(2)根据贪心策略,按照性价比从大到小选取宝物,直到达到毛驴的运载能力。每次选择性价比高的物品,判断是否小于m(毛驴运载能力),如果小于m,则放入,sum(已放入物品的价值)加上当前宝物的价值,m减去放入宝物的重量;如果不小于m,则取该宝物的一部分m * p[i],m=0,程序结束。m减少到0,则sum得到最大值。
2.3.3 完美图解
假设现在有一批宝物,价值和重量如表 2-3 所示,毛驴运载能力 m=30,那么怎么装入最大价值的物品?
| 宝物i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- |
| 重量w[i] | 4 | 2 | 9 | 5 | 5 | 8 | 5 | 4 | 5 | 5 |
| 价值v[i] | 3 | 8 | 18 | 6 | 8 | 20 | 5 | 6 | 7 | 15 |
(1)因为贪心策略是每次选择性价比(价值/重量)高的宝物,可以按照性价比降序排序,排序后如表2-4所示。
| 宝物i | 2 | 10 | 6 | 3 | 5 | 8 | 9 | 4 | 7 | 1 |
| :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- |
| 重量w[i] | 2 | 5 | 8 | 9 | 5 | 4 | 5 | 5 | 5 | 4 |
| 价值v[i] | 8 | 15 | 20 | 18 | 8 | 6 | 7 | 6 | 5 | 3 |
| 性价比p[i] | 4 | 3 | 2.5 | 2 | 1.6 | 1.5 | 1.4 | 1.2 | 1 | 0.75 |
(2)按照贪心策略,每次选择性价比高的宝物放入:
第1次选择宝物2,剩余容量30−2=28,目前装入最大价值为8。
第2次选择宝物10,剩余容量28−5=23,目前装入最大价值为8+15=23。
第3次选择宝物6,剩余容量23−8=15,目前装入最大价值为23+20=43。
第4次选择宝物3,剩余容量15−9=6,目前装入最大价值为43+18=61。
第5次选择宝物5,剩余容量6−5=1,目前装入最大价值为61+8=69。
第6次选择宝物8,发现上次处理完时剩余容量为1,而8号宝物重量为4,无法全部放入,那么可以采用部分装入的形式,装入1个重量单位,因为8号宝物的单位重量价值为1.5,因此放入价值1×1.5=1.5,你也可以认为装入了8号宝物的1/4,目前装入最大价值为69+1.5=70.5,剩余容量为0。
(3)构造最优解
把这些放入的宝物序号组合在一起,就得到了最优解(2,10,6,3,5,8),其中最后一个宝物为部分装入(装了8号财宝的1/4),能够装入宝物的最大价值为70.5。
2.3.4 伪代码详解
(1)数据结构定义
根据算法设计中的数据结构,我们首先定义一个结构体three:
1 | struct three{ |
(2)性价比排序
我们可以利用C++中的排序函数sort(见附录B),对宝物的性价比从大到小(非递增)排序。要使用此函数需引入头文件:
1 |
语法描述为:
1 | sort(begin, end)// 参数begin和end表示一个范围,分别为待排序数组的首地址和尾地址 |
在本例中我们采用结构体形式存储,按结构体中的一个字段,即按性价比排序。如果不使用自定义比较函数,那么sort函数排序时不知道按哪一项的值排序,因此采用自定义比较函数的办法实现宝物性价比的降序排序:
1 | bool cmp(three a,three b)//比较函数按照宝物性价比降序排列 |
(3)贪心算法求解
在性价比排序的基础上,进行贪心算法运算。如果剩余容量比当前宝物的重量大,则可以放入,剩余容量减去当前宝物的重量,已放入物品的价值加上当前宝物的价值。如果剩余容量比当前宝物的重量小,表示不可以全部放入,可以切割下来一部分(正好是剩余容量),然后令剩余容量乘以当前物品的单位重量价值,已放入物品的价值加上该价值,即为能放入宝物的最大价值。
1 | for(int i = 0;i < n;i++)//按照排好的顺序,执行贪心策略 |
2.3.5 实战演练
1 | //program 2-2 |
算法实现和测试
(1)运行环境
Code::Blocks
(2)输入
1 | 6 19 //宝物数量,驴子的承载重量 |
(3)输出
1 | Maxinum value=24.6 |
2.3.6 算法解析及优化拓展
1.算法复杂度分析
(1)时间复杂度:该算法的时间主要耗费在将宝物按照性价比排序上,采用的是快速排序,算法时间复杂度为O(nlogn)。
(2)空间复杂度:空间主要耗费在存储宝物的性价比,空间复杂度为O(n)。
为了使 m 重量里的所有物品的价值最大,利用贪心思想,每次取剩下物品里面性价比最高的物品,这样可以使得在相同重量条件下比选其他物品所得到的价值更大,因此采用贪心策略能得到最优解。
2.算法优化拓展
那么想一想,如果宝物不可分割,贪心算法是否能得到最优解?
下面我们看一个简单的例子。
假定物品的重量和价值已知,如表2-5所示,最大运载能力为10。采用贪心算法会得到怎样的结果?
| 物品i | 1 | 2 | 3 | 4 | 5 |
| :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- |
| 重量w[i] | 3 | 4 | 6 | 10 | 7 |
| 价值v[i] | 15 | 16 | 18 | 25 | 14 |
| 性价比p[i] | 5 | 4 | 3 | 2.5 | 2 |
如果我们采用贪心算法,先装性价比高的物品,且物品不能分割,剩余容量如果无法再装入剩余的物品,不管还有没有运载能力,算法都会结束。那么我们选择的物品为 1和2,总价值为 31,而实际上还有 3 个剩余容量,但不足以装下剩余其他物品,因此得到的最大价值为31。但实际上我们如果选择物品2和3,正好达到运载能力,得到的最大价值为34。也就是说,在物品不可分割、没法装满的情况下,贪心算法并不能得到最优解,仅仅是最优解的近似解。
想一想,为什么会这样呢?
物品可分割的装载问题我们称为 背包问题 ,物品不可分割的装载问题我们称之为 0-1背包问题 。
在物品不可分割的情况下,即0-1背包问题,已经不具有贪心选择性质,原问题的整体最优解无法通过一系列局部最优的选择得到,因此这类问题得到的是近似解。如果一个问题不要求得到最优解,而只需要一个最优解的近似解,则不管该问题有没有贪心选择性质都可以使用贪心算法。
想一想,2.3节中加勒比海盗船问题为什么在没有装满的情况下,仍然是最优解,而0-1背包问题在没装满的情况下有可能只是最优解的近似解?
2.4 高级钟点秘书——会议安排
所谓“钟点秘书”,是指年轻白领女性利用工余时间为客户提供秘书服务,并按钟点收取酬金。
“钟点秘书”为客户提供有偿服务的方式一般是:采用电话、电传、上网等“遥控”式服务,或亲自到客户公司处理部分业务。其服务对象主要有三类:一是外地前来考察商务经营、项目投资的商人或政要人员,他们由于初来乍到,急需有经验和熟悉本地情况的秘书帮忙;二是前来开展短暂商务活动,或召开小型资讯发布会的国外客商;三是本地一些请不起长期秘书的企、事业单位。这些客户普遍认为:请“钟点秘书”,一则可免去专门租楼请人的大笔开销;二则可根据开展的商务活动请有某方面专长的可用人才;三则由于对方是临时雇用关系,工作效率往往比固定的秘书更高。据调查,在上海“钟点秘书”的行情日趋看好。对此,业内人士认为:为了便于管理,各大城市有必要组建若干家“钟点秘书服务公司”,通过会员制的形式,为众多客户提供规范、优良、全面的服务,这也是建设国际化大都市所必需的。
某跨国公司总裁正分身无术,为一大堆会议时间表焦头烂额,希望高级钟点秘书能做出合理的安排,能在有限的时间内召开更多的会议。

2.4.1 问题分析
这是一个典型的会议安排问题,会议安排的目的是能在有限的时间内召开更多的会议(任何两个会议不能同时进行)。在会议安排中,每个会议i都有起始时间bi和结束时间ei,且bi<ei,即一个会议进行的时间为半开区间[bi,ei)。如果[bi,ei)与[bj,ej)均在“有限的时间内”,且不相交,则称会议i与会议j相容的。也就是说,当bi≥ej或bj≥ei时,会议i与会议j相容。会议安排问题要求在所给的会议集合中选出最大的相容活动子集,即尽可能在有限的时间内召开更多的会议。
在这个问题中,“有限的时间内(这段时间应该是连续的)”是其中的一个限制条件,也应该是有一个起始时间和一个结束时间(简单化,起始时间可以是会议最早开始的时间,结束时间可以是会议最晚结束的时间),任务就是实现召开更多的满足在这个“有限的时间内”等待安排的会议,会议时间表如表2-6所示。
| 会议i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- |
| 开始时间bi | 8 | 9 | 10 | 11 | 13 | 14 | 15 | 17 | 18 | 16 |
| 结束时间ei | 10 | 11 | 15 | 14 | 16 | 17 | 17 | 18 | 20 | 19 |
会议安排的时间段如图2-7所示。
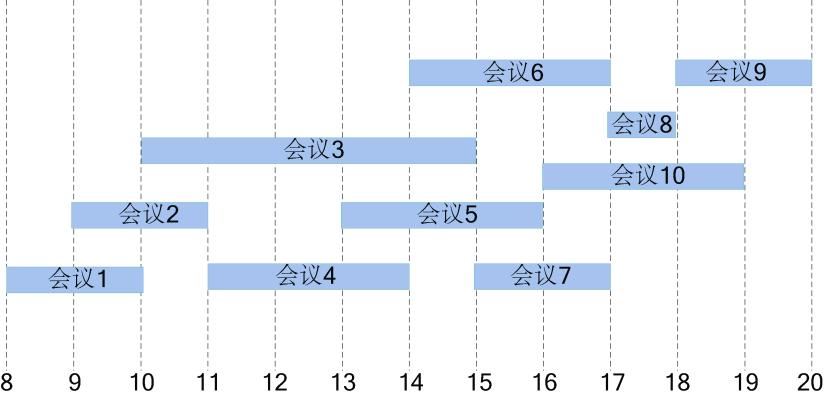
从图2-7中可以看出,{会议1,会议4,会议6,会议8,会议9},{会议2,会议4,会议7,会议8,会议9}都是能安排最多的会议集合。
要让会议数最多,我们需要选择最多的不相交时间段。我们可以尝试贪心策略:
(1)每次从剩下未安排的会议中选择会议 具有最早开始时间且与已安排的会议相容 的会议安排,以增大时间资源的利用率。
(2)每次从剩下未安排的会议中选择 持续时间最短且与已安排的会议相容 的会议安排,这样可以安排更多一些的会议。
(3)每次从剩下未安排的会议中选择 具有最早结束时间且与已安排的会议相容 的会议安排,这样可以尽快安排下一个会议。
思考一下,如果选择最早开始时间,则如果会议持续时间很长,例如8点开始,却要持续12个小时,这样一天就只能安排一个会议;如果选择持续时间最短,则可能开始时间很晚,例如19点开始,20点结束,这样也只能安排一个会议,所以我们最好选择那些开始时间要早,而且持续时间短的会议,即最早开始时间+持续时间最短,就是 最早结束 时间。
因此采用第(3)种 贪心策略,每次从剩下的会议中选择具有最早结束时间且与已安排的会议相容的会议安排 。
2.4.2 算法设计
(1)初始化:将n个会议的开始时间、结束时间存放在结构体数组中(想一想,为什么不用两个一维数组分别存储?),如果需要知道选中了哪些会议,还需要在结构体中增加会议编号,然后按结束时间从小到大排序(非递减),结束时间相等时,按开始时间从大到小排序(非递增);
(2)根据贪心策略就是选择第一个具有最早结束时间的会议,用last记录刚选中会议的结束时间;
(3)选择第一个会议之后,依次 从剩下未安排的会议中选择 ,如果会议i开始时间大于等于最后一个选中的会议的结束时间last,那么会议i与已选中的会议相容,可以安排,更新last为刚选中会议的结束时间;否则,舍弃会议i,检查下一个会议是否可以安排。
2.4.3 完美图解
1.原始的会议时间表(见表2-7):
| 会议num | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- |
| 开始时间beg | 3 | 1 | 5 | 2 | 5 | 3 | 8 | 6 | 8 | 12 |
| 结束时间end | 6 | 4 | 7 | 5 | 9 | 8 | 11 | 10 | 12 | 14 |
2.排序后的会议时间表(见表2-8):
| 会议num | 2 | 4 | 1 | 3 | 6 | 5 | 8 | 7 | 9 | 10 |
| :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- |
| 开始时间beg | 1 | 2 | 3 | 5 | 3 | 5 | 6 | 8 | 8 | 12 |
| 结束时间end | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 14 |
3.贪心选择过程
(1)首先选择排序后的第一个会议即最早结束的会议(编号为2),用last记录最后一个被选中会议的结束时间,last=4。
(2)检查余下的会议,找到第一个开始时间大于等于 last(last=4)的会议,子问题转化为从该会议开始,余下的所有会议。如表2-9所示。

从子问题中,选择第一个会议即最早结束的会议(编号为3),更新last为刚选中会议的结束时间last=7。
(3)检查余下的会议,找到第一个开始时间大于等于last(last=7)的会议,子问题转化为从该会议开始,余下的所有会议。如表2-10所示。

从子问题中,选择第一个会议即最早结束的会议(编号为 7),更新 last 为刚选中会议的结束时间last=11。
(4)检查余下的会议,找到第一个开始时间大于等于last(last=11)的会议,子问题转化为从该会议开始,余下的所有会议。如表2-11所示。

从子问题中,选择第一个会议即最早结束的会议(编号为10),更新last为刚选中会议的结束时间last=14;所有会议检查完毕,算法结束。如表2-12所示。
4.构造最优解
从贪心选择的结果,可以看出,被选中的会议编号为{2,3,7,10},可以安排的会议数量最多为4,如表2-12所示。

2.4.4 伪代码详解
(1)数据结构定义
以下C++程序代码中,结构体meet中定义了beg表示会议的开始时间,end表示会议的结束时间,会议meet的数据结构:
1 | struct Meet |
(2)对会议按照结束时间非递减排序
我们采用C++中自带的sort函数,自定义比较函数的办法,实现会议排序,按结束时间从小到大排序(非递减),结束时间相等时,按开始时间从大到小排序(非递增):
1 | bool cmp(Meet x,Meet y) |
(3)会议安排问题的贪心算法求解
在会议按结束时间非递减排序的基础上,首先选中第一个会议,用last变量记录刚刚被选中会议的结束时间。下一个会议的开始时间与last比较,如果大于等于last,则选中。每次选中一个会议,更新last为最后一个被选中会议的结束时间,被选中的会议数ans加1;如果会议的开始时间不大于等于last,继续考查下一个会议,直到所有会议考查完毕。
1 | int ans=1; //用来记录可以安排会议的个数,初始时选中了第一个会议 |
上面介绍的程序中,只是返回了可以安排的会议最大数,而不知道安排了哪些会议,这显然是不满足需要的。我们可以改进一下,在会议结构体meet中添加会议编号num变量,选中会议时,显示选中了第几个会议。
2.4.5 实战演练
1 | //program 2-3 |
算法实现和测试
(1)运行环境
Code::Blocks
(2)输入
1 | 输入会议总数: |
(3)输出
1 | 排完序的会议时间如下: |
使用上面贪心算法可得,选择的会议是第2、3、7、10个会议,输出最优值是4。
2.4.6 算法解析及优化拓展
1.算法复杂度分析
(1)时间复杂度:在该算法中,问题的规模就是会议总个数n。显然,执行次数随问题规模的增大而变化。首先在成员函数setMeet::init()中,输入n个结构体数据。输入作为基本语句,显然,共执行n次。而后在调用成员函数setMeet::solve()中进行排序,易知sort排序函数的平均时间复杂度为O(nlogn)。随后进行选择会议,贡献最大的为if(meet[i].beg>=last)语句,时间复杂度为O(n),总时间复杂度为O(n +nlogn)= O(nlogn)。
(2)空间复杂度:在该算法中,meet[]结构体数组为输入数据,不计算在空间复杂度内。辅助空间有i、n、ans等变量,则该程序空间复杂度为常数阶,即O(1)。
2.算法优化拓展
想一想,你有没有更好的办法来处理此问题,比如有更小的算法时间复杂度?
2.5 一场说走就走的旅行——最短路径
有一天,孩子回来对我说:“妈妈,听说马尔代夫很不错,放假了我想去玩。”马尔代夫?我也想去!没有人不向往一场说走就走的旅行!“其实我想去的地方很多,呼伦贝尔大草原、玉龙雪山、布达拉宫、艾菲尔铁塔……”小孩子还说着他感兴趣的地方。于是我们拿出地图,标出想去的地点,然后计算最短路线,估算大约所需的时间,有了这张秘制地图,一场说走就走的旅行不是梦!
“哇,感觉我们像凡尔纳的《环游地球八十天》,好激动!可是老妈你也太out了,学计算机的最短路线你用手算?”
暴汗……,“小子你别牛,你知道怎么算?”
“呃,好像是叫什么迪科斯彻的人会算。”
哈哈,关键时刻还要老妈上场了!

2.5.1 问题分析
根据题目描述可知,这是一个求单源最短路径的问题。给定有向带权图G =(V,E),其中每条边的权是非负实数。此外,给定V中的一个顶点,称为源点。现在要计算从源到所有其他各顶点的最短路径长度,这里路径长度指路上各边的权之和。
如何求源点到其他各点的最短路径呢?
如图2-9所示,艾兹格•W•迪科斯彻(Edsger Wybe Dijkstra),荷兰人,计算机科学家。他早年钻研物理及数学,后转而研究计算学。他曾在1972年获得过素有“计算机科学界的诺贝尔奖”之称的图灵奖,与Donald Ervin Knuth并称为我们这个时代最伟大的计算机科学家。

2.5.2 算法设计
Dijkstra 算法是解决单源最短路径问题的贪心算法,它先求出长度最短的一条路径,再参照该最短路径求出长度次短的一条路径,直到求出从源点到其他各个顶点的最短路径。
Dijkstra算法的基本思想是首先假定源点为u,顶点集合V被划分为两部分:集合S和 V−S。初始时 S 中仅含有源点 u,其中 S 中的顶点到源点的最短路径已经确定。集合V−S中所包含的顶点到源点的最短路径的长度待定,称从源点出发只经过S中的点到达V−S中的点的路径为特殊路径,并用数组dist[]记录当前每个顶点所对应的最短特殊路径长度。
Dijkstra算法采用的贪心策略是选择特殊路径长度最短的路径,将其连接的V−S中的顶点加入到集合S中,同时更新数组dist[]。一旦S包含了所有顶点,dist[]就是从源到所有其他顶点之间的最短路径长度。
(1)数据结构。设置地图的带权邻接矩阵为map[][],即如果从源点u到顶点i有边,就令 map[u][i]等于<u,i>的权值,否则 map[u][i]=∞(无穷大);采用一维数组 dist[i]来记录从源点到i顶点的最短路径长度;采用一维数组p[i]来记录最短路径上i顶点的前驱。
(2)初始化。令集合S={u},对于集合V−S中的所有顶点x,初始化dist[i]=map[u][i],如果源点u到顶点i有边相连,初始化p[i]=u,否则p[i]= −1。
(3)找最小。在集合V−S中依照贪心策略来寻找使得dist[j]具有最小值的顶点t,即dist[t]=min(dist[j]|j属于V−S集合),则顶点t就是集合V−S中距离源点u最近的顶点。
(4)加入S战队。将顶点t加入集合S中,同时更新V−S。
(5)判结束。如果集合V−S为空,算法结束,否则转(6)。
(6)借东风。在(3)中已经找到了源点到t的最短路径,那么对集合V−S中所有与顶点t相邻的顶点j,都可以借助t走捷径。如果dis[j]>dist[t]+map[t][j],则dist[j]=dist[t]+map[t][j],记录顶点j的前驱为t,有p[j]= t,转(3)。
由此,可求得从源点u到图G的其余各个顶点的最短路径及长度,也可通过数组p[]逆向找到最短路径上经过的城市。
2.5.3 完美图解
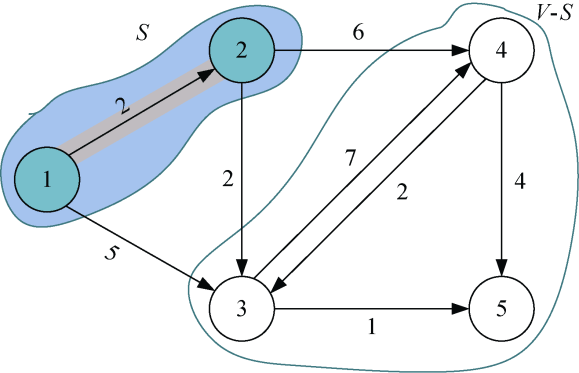
现在我们有一个景点地图,如图2-10所示,假设从1号结点出发,求到其他各个结点的最短路径。
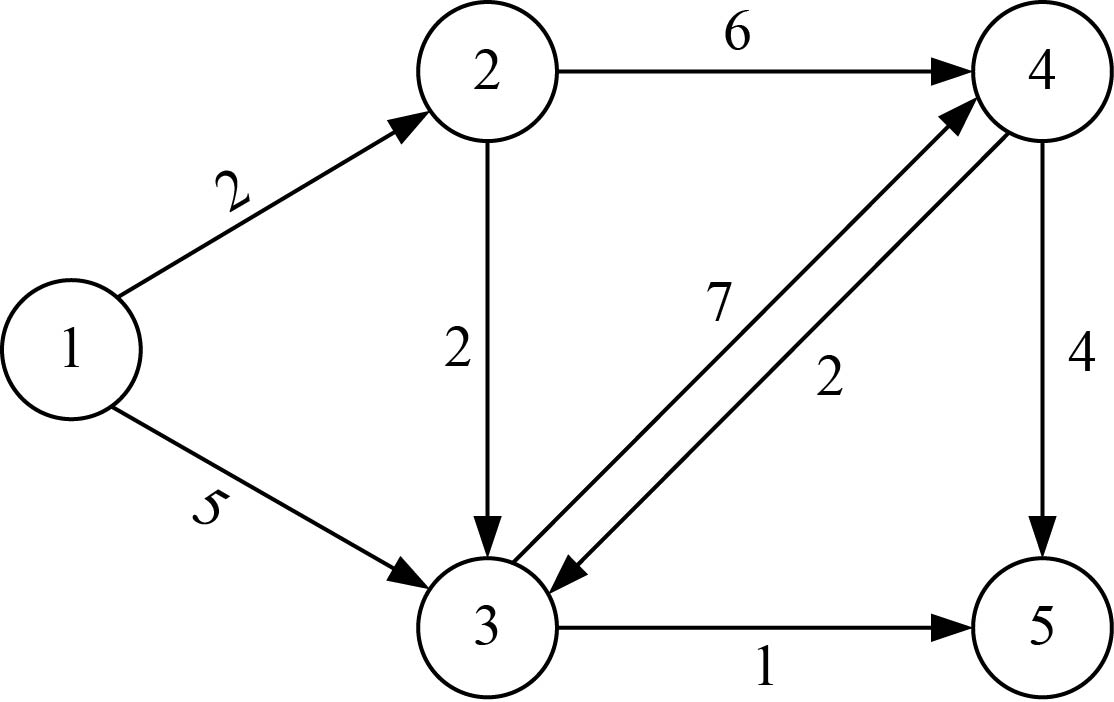
算法步骤如下。
(1)数据结构
设置地图的带权邻接矩阵为map[][],即如果从顶点i到顶点j有边,则map[i][j]等于<i,j>的权值,否则map[i][j]=∞(无穷大),如图2-11所示。

(2)初始化
令集合S={1},V−S={2,3,4,5},对于集合V−S中的所有顶点x,初始化最短距离数组dist[i]=map[1][i],dist[u]=0,如图2-12所示。如果源点1到顶点i有边相连,初始化前驱数组p[i]=1,否则p[i]= −1,如图2-13所示。

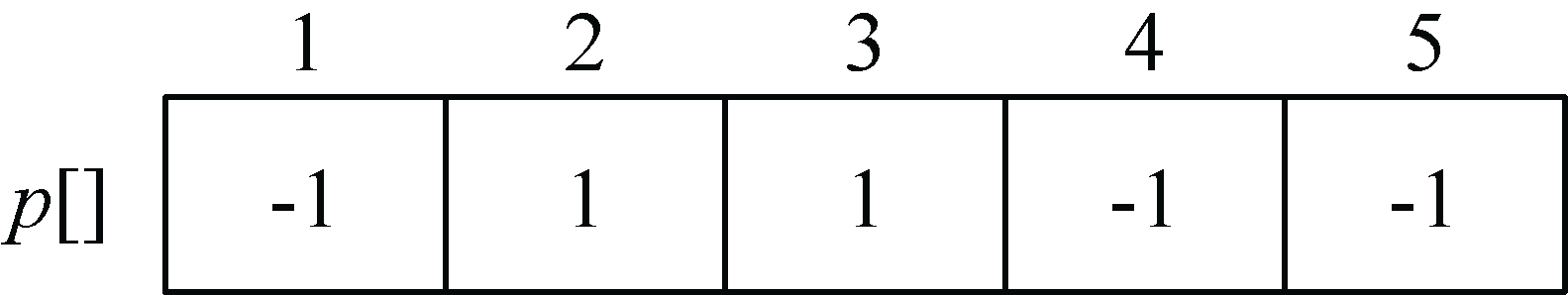
(3)找最小
在集合V−S={2,3,4,5}中,依照贪心策略来寻找V−S集合中dist[]最小的顶点t,如图2-14所示。
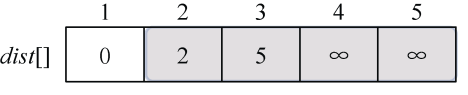
找到最小值为2,对应的结点t=2。
(4)加入S战队
将顶点t=2加入集合S中S={1,2},同时更新V−S={3,4,5},如图2-15所示。
(5)借东风
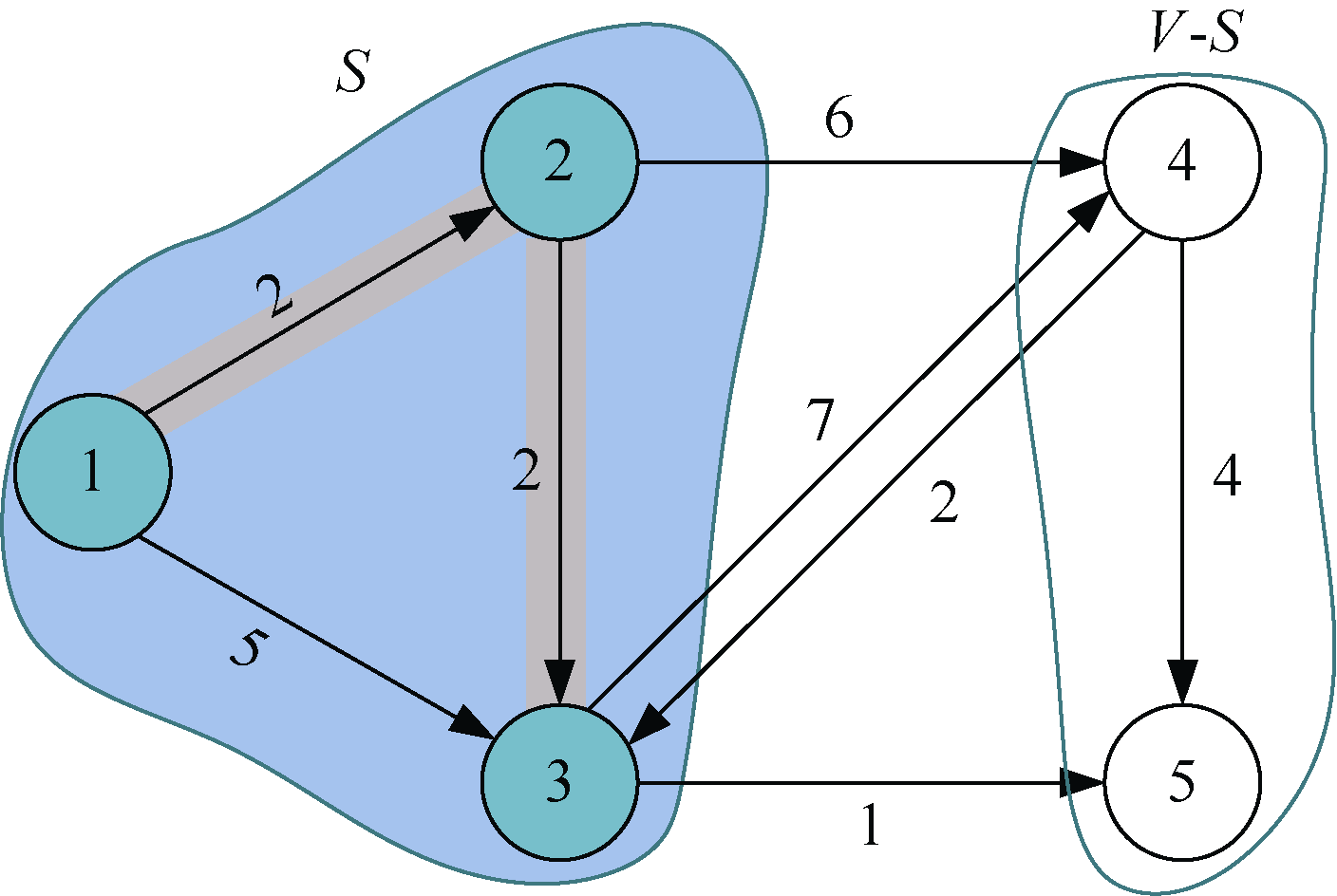
刚刚找到了源点到t=2的最短路径,那么对集合V−S中所有t的邻接点j,都可以借助t走捷径。我们从图或邻接矩阵都可以看出,2号结点的邻接点是3和4号结点,如图2-16所示。
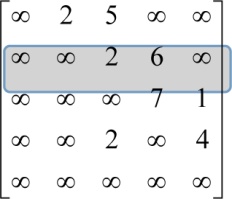
先看3号结点能否借助2号走捷径:dist[2]+map[2][3]=2+2=4,而当前dist[3]=5>4,因此可以走捷径即2—3,更新dist[3]=4,记录顶点3的前驱为2,即p[3]= 2。
再看4号结点能否借助2号走捷径:如果dist[2]+map[2][4]=2+6=8,而当前dist[4]=∞>8,因此可以走捷径即2—4,更新dist[4]=8,记录顶点4的前驱为2,即p[4]= 2。
更新后如图2-17和图2-18所示。


(6)找最小
在集合V−S={3,4,5}中,依照贪心策略来寻找dist[]具有最小值的顶点t,依照贪心策略来寻找V−S集合中dist[]最小的顶点t,如图2-19所示。
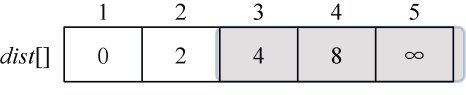
找到最小值为4,对应的结点t=3。
(7)加入S战队
将顶点t=3加入集合S中S={1,2,3},同时更新V−S={4,5},如图2-20所示。
(8)借东风
刚刚找到了源点到t =3的最短路径,那么对集合V−S中所有t的邻接点j,都可以借助t走捷径。我们从图或邻接矩阵可以看出,3号结点的邻接点是4和5号结点。
先看4号结点能否借助3号走捷径:dist[3]+map[3][4]=4+7=11,而当前dist[4]=8<11,比当前路径还长,因此不更新。
再看5号结点能否借助3号走捷径:dist[3]+map[3][5]=4+1=5,而当前dist[5]=∞>5,因此可以走捷径即3—5,更新dist[5]=5,记录顶点5的前驱为3,即p[5]=3。
更新后如图2-21和图2-22所示。
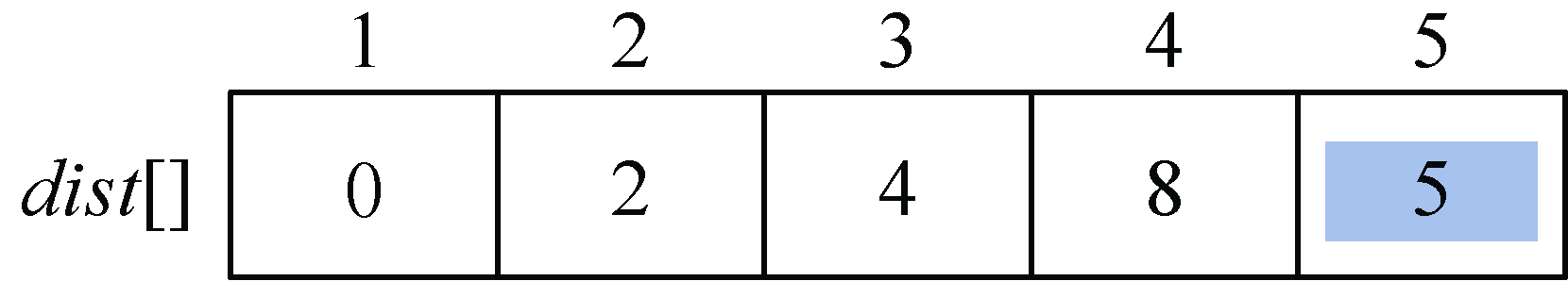

(9)找最小
在集合V−S={4,5}中,依照贪心策略来寻找V−S集合中dist[]最小的顶点t,如图2-23所示。
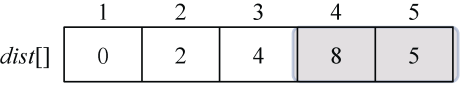
找到最小值为5,对应的结点t=5。
(10)加入S战队
将顶点t=5加入集合S中S={1,2,3,5},同时更新V−S={4},如图2-24所示。
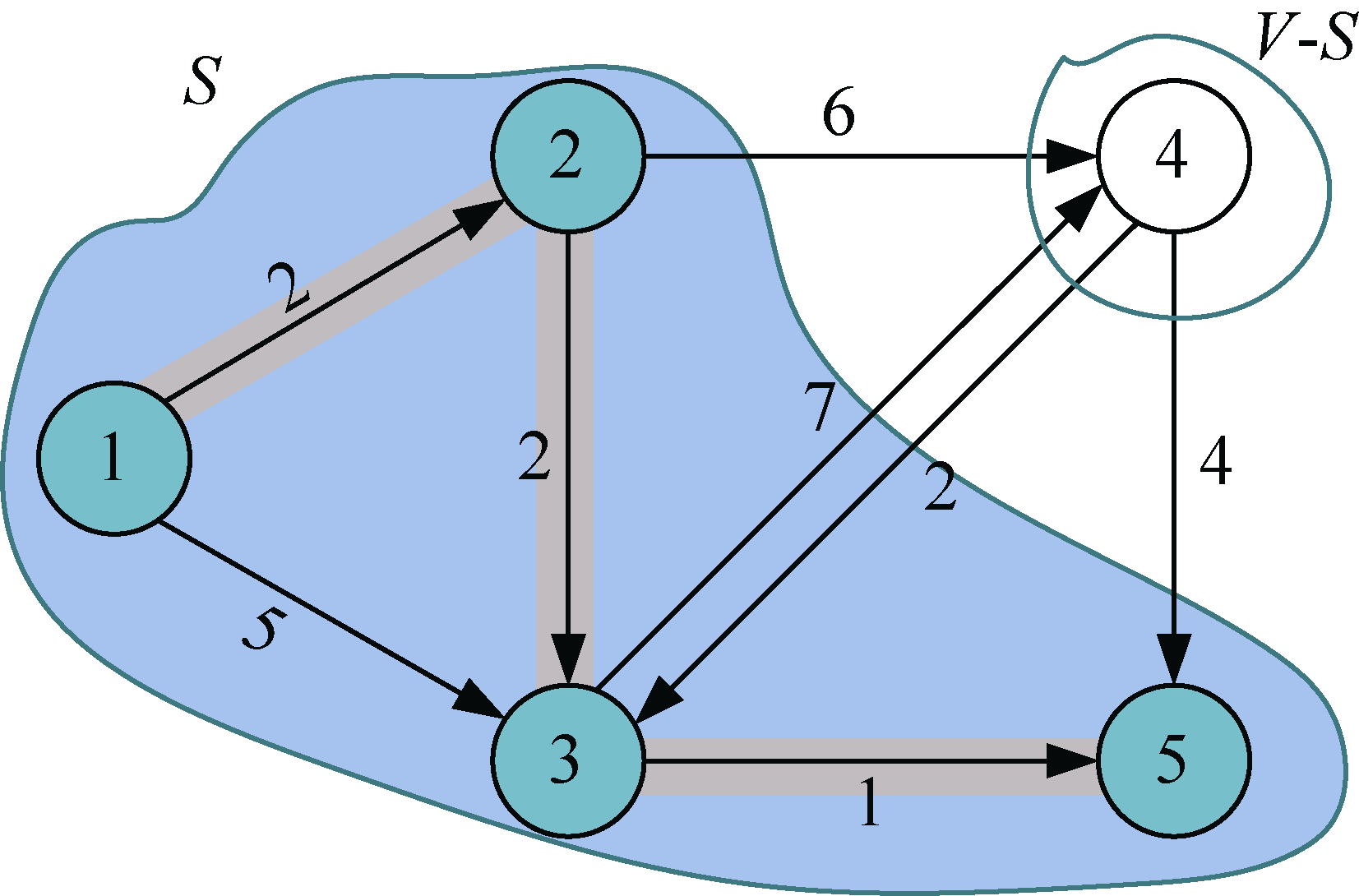
(11)借东风
刚刚找到了源点到t =5的最短路径,那么对集合V−S中所有t的邻接点j,都可以借助t走捷径。我们从图或邻接矩阵可以看出,5号结点没有邻接点,因此不更新,如图2-25和图2-26所示。
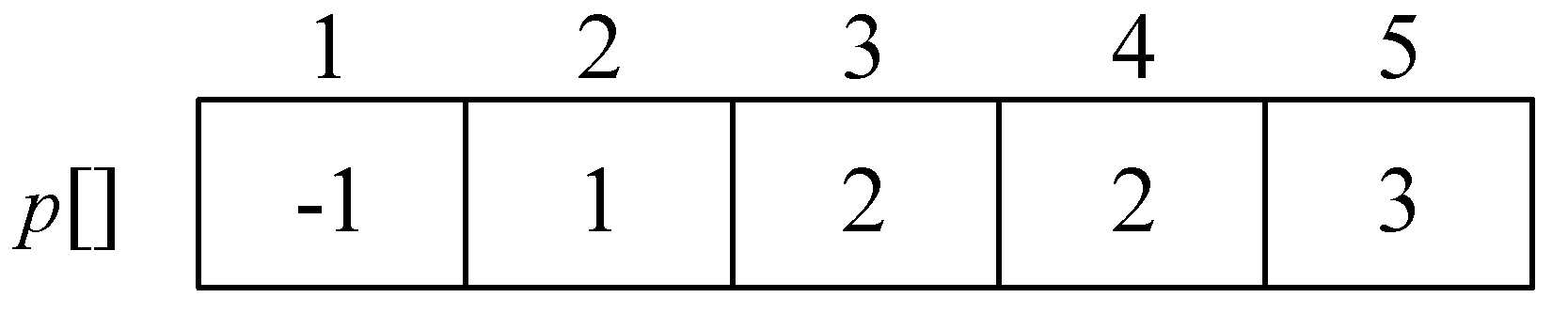
(12)找最小
在集合V−S={4}中,依照贪心策略来寻找dist[]最小的顶点t,只有一个顶点,所以很容易找到,如图2-27所示。
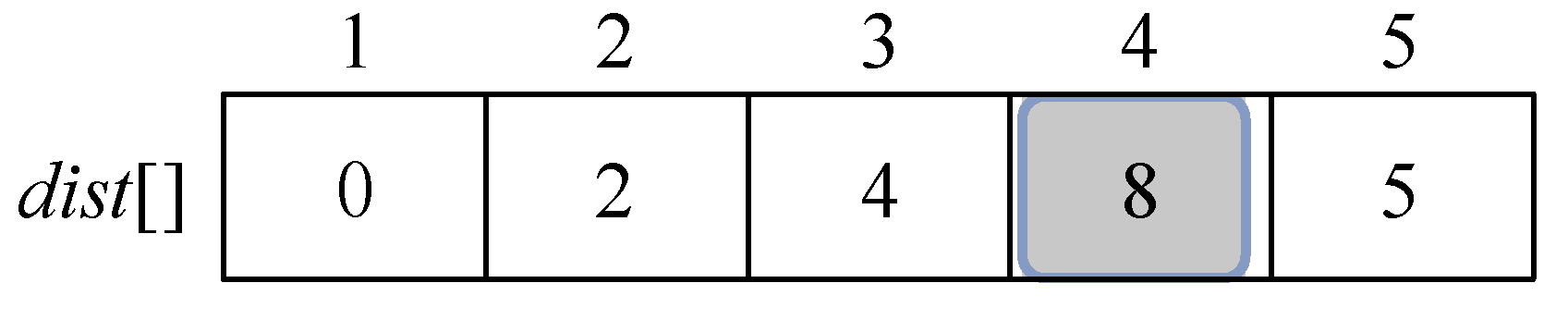
找到最小值为8,对应的结点t=4。
(13)加入S战队
将顶点t加入集合S中S={1,2,3,5,4},同时更新V−S={ },如图2-28所示。
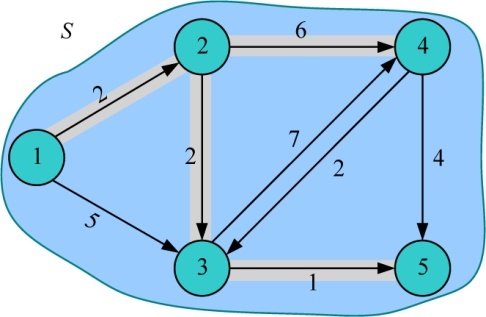
(14)算法结束
V−S={ }为空时,算法停止。
由此,可求得从源点u到图G的其余各个顶点的最短路径及长度,也可通过前驱数组p[]逆向找到最短路径上经过的城市,如图2-29所示。
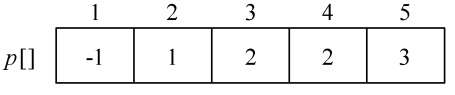
例如,p[5]=3,即5的前驱是3;p[3]=2,即3的前驱是2;p[2]=1,即2的前驱是1;p[1]= −1,1没有前驱,那么从源点1到5的最短路径为1—2—3—5。
2.5.4 伪代码详解
(1)数据结构
n:城市顶点个数。m:城市间路线的条数。map[][]:地图对应的带权邻接矩阵。dist[]:记录源点u到某顶点的最短路径长度。p[]:记录源点到某顶点的最短路径上的该顶点的前一个顶点(前驱)。flag[]:flag[i]等于true,说明顶点i已经加入到集合S,否则顶点i属于集合V−S。
1 | const int N = 100; //初始化城市的个数,可修改 |
(2)初始化源点u到其他各个顶点的最短路径长度,初始化源点u出边邻接点(t的出边相关联的顶点)的前驱为u:
1 | bool flag[n];//如果flag[i]等于true,说明顶点i已经加入到集合S;否则i属于集合V-S |
(3)初始化集合S,令集合S={u},从源点到u的最短路径为0。
1 | flag[u]=true; //初始化集合S中,只有一个元素:源点 u |
(4)找最小
在集合V−S中寻找距离源点u最近的顶点t,若找不到t,则跳出循环;否则,将t加入集合S。
1 | int temp = INF,t = u ; |
(5)借东风
考查集合V−S中源点u到t的邻接点j的距离,如果源点u经过t到达j的路径更短,则更新dist[j] =dist[t]+map[t][j],即松弛操作,并记录j的前驱为t:
1 | for(int j = 1; j <= n; j ++) //更新集合V-S中与t邻接的顶点到源点u的距离 |
重复(4)~(5),直到源点u到所有顶点的最短路径被找到。
2.5.5 实战演练
1 | //program 2-4 |
算法实现和测试
(1)运行环境
Code::Blocks
(2)输入
1 | 请输入城市的个数: |
(3)输出
1 | 小明所在的位置:5 |
想一想:因为我们在程序中使用p[]数组记录了最短路径上每一个结点的前驱,因此除了显示最短距离外,还可以显示最短路径上经过了哪些城市,可以增加一段程序逆向找到该最短路径上的城市序列。
1 | void findpath(int u) |
只需要在主函数末尾调用该函数:
1 | findpath(st);//主函数中st为源点 |
输出结果如下。
1 | 源点为:5 |
2.5.6 算法解析及优化拓展
1.算法时间复杂度
(1)时间复杂度:在Dijkstra算法描述中,一共有4个for语句,第①个for语句的执行次数为n,第②个for语句里面嵌套了两个for语句③、④,它们的执行次数均为n,对算法的运行时间贡献最大,当外层循环标号为1时,③、④语句在内层循环的控制下均执行n次,外层循环②从1~n。因此,该语句的执行次数为n*n= n²,算法的时间复杂度为O(n²)。
(2)空间复杂度:由以上算法可以得出,实现该算法所需要的辅助空间包含为数组flag、变量i、j、t和temp所分配的空间,因此,空间复杂度为O(n)。
2.算法优化拓展
在for语句③中,即在集合V−S中寻找距离源点u最近的顶点t,其时间复杂度为O(n),如果我们使用优先队列,则可以把时间复杂度降为O(log n)。那么如何使用优先队列呢?
(1)优先队列(见附录C)
(2)数据结构
在上面的例子中,我们使用了一维数组dist[t]来记录源点u到顶点t的最短路径长度。在此为了操作方便,我们使用结构体的形式来实现,定义一个结构体Node,里面包含两个成员:u为顶点,step为源点到顶点u的最短路径。
1 | struct Node{ |
上面的结构体中除了两个成员变量外,还有一个构造函数和运算符优先级重载,下面详细介绍其含义用途。
为什么要使用构造函数?
如果不使用构造函数也是可以的,只定义一般的结构体,里面包含两个参数:
1 | struct Node{ |
那么在变量参数赋值时,需要这样赋值:
1 | Node vs ; //先定义一个Node结点类型变量 |
采用构造函数的形式定义结构体:
1 | struct Node{ |
则变量参数赋值就可以直接通过参数传递:
1 | Node vs(3,5) |
上面语句等价于:
1 | vs.v =3 ,vs.step = 5; |
很明显通过构造函数的形式定义结构体,参数赋值更方便快捷,后面程序中会将结点压入优先队列:
1 | priority_queue <Node> Q; // 创建优先队列,最小值优先 |
(3)使用优先队列优化的Dijkstra算法源代码:
1 | //program 2-5 |
算法实现和测试
(1)运行环境
Code::Blocks
(2)输入
1 | 请输入城市的个数: |
(3)输出
1 | 小明所在的位置:1 |
在使用优先队列的 Dijkstra 算法描述中,while (!Q.empty())语句执行的次数为n,因为要弹出n个最小值队列才会空;Q.pop()语句的时间复杂度为logn,while语句中的for语句执行n次,for语句中的Q.push (Node(i,dist[i]))时间复杂度为logn。因此,总的语句的执行次数为n* logn+n²*logn,算法的时间复杂度为O(n²logn)。
貌似时间复杂度又变大了?
这是因为我们采用的邻接矩阵存储的,如果采用邻接表存储(见附录D),那么for语句④松弛操作就不用每次执行n次,而是执行t结点的邻接边数x,每个结点的邻接边加起来为边数E,那么总的时间复杂度为O(nlogn+Elogn),如果E≥n,则时间复杂度为O(E*logn)。
注意: 优先队列中尽管有重复的结点,但重复结点最坏是n2,log n2=2 log n,并不改变时间复杂度的数量级。
想一想,还能不能把时间复杂度再降低呢?如果我们使用斐波那契堆,那么松弛操作的时间复杂度O(1),总的时间复杂度为O(n* logn+E)。
2.6 神秘电报密码——哈夫曼编码
看过谍战电影《风声》的观众都会对影片中神奇的消息传递惊叹不已!吴志国大队长在受了残忍的“针刑”之后躺在手术台上唱空城计,变了音调,把消息传给了护士,顾晓梦在衣服上缝补了长短不一的针脚……那么,片中无处不在的摩尔斯码到底是什么?它又有着怎样的神秘力量呢?
摩尔斯电码(Morse code)由点dot(. )、划dash(-)两种符号组成。它的基本原理是:把英文字母表中的字母、标点符号和空格按照出现的频率排序,然后用点和划的组合来代表这些字母、标点符号和空格,使频率最高的符号具有最短的点划组合。

2.6.1 问题分析
我们先看一个生活中的例子:
有一群退休的老教授聚会,其中一个老教授带着刚会说话的漂亮小孙女,于是大家逗她:“你能猜猜我们多大了吗?猜对了有糖吃哦!”小女孩就开始猜:“你是1岁了吗?”,老教授摇摇头。“你是两岁了吗?”,老教授仍然摇摇头。“那一定是3岁了!”……大家哈哈大笑。或许我们都感觉到了小女孩的天真可爱,然而生活中的确有很多类似这样的判断。
曾经有这样一个C++设计题目:将一个班级的成绩从百分制转为等级制。一同学设计的程序为:
1 | if(score <60) cout << "不及格"<<endl; |
在上面程序中,如果分数小于60,我们做1次判定即可;如果分数为60~70,需要判定2次;如果分数为70~80,需要判定3次;如果分数为80~90,需要判定4次;如果分数为90~100,需要判定5次。
这段程序貌似是没有任何问题,但是我们却犯了从1岁开始判断一个老教授年龄的错误,因为我们的考试成绩往往是呈正态分布的,如图2-31所示。
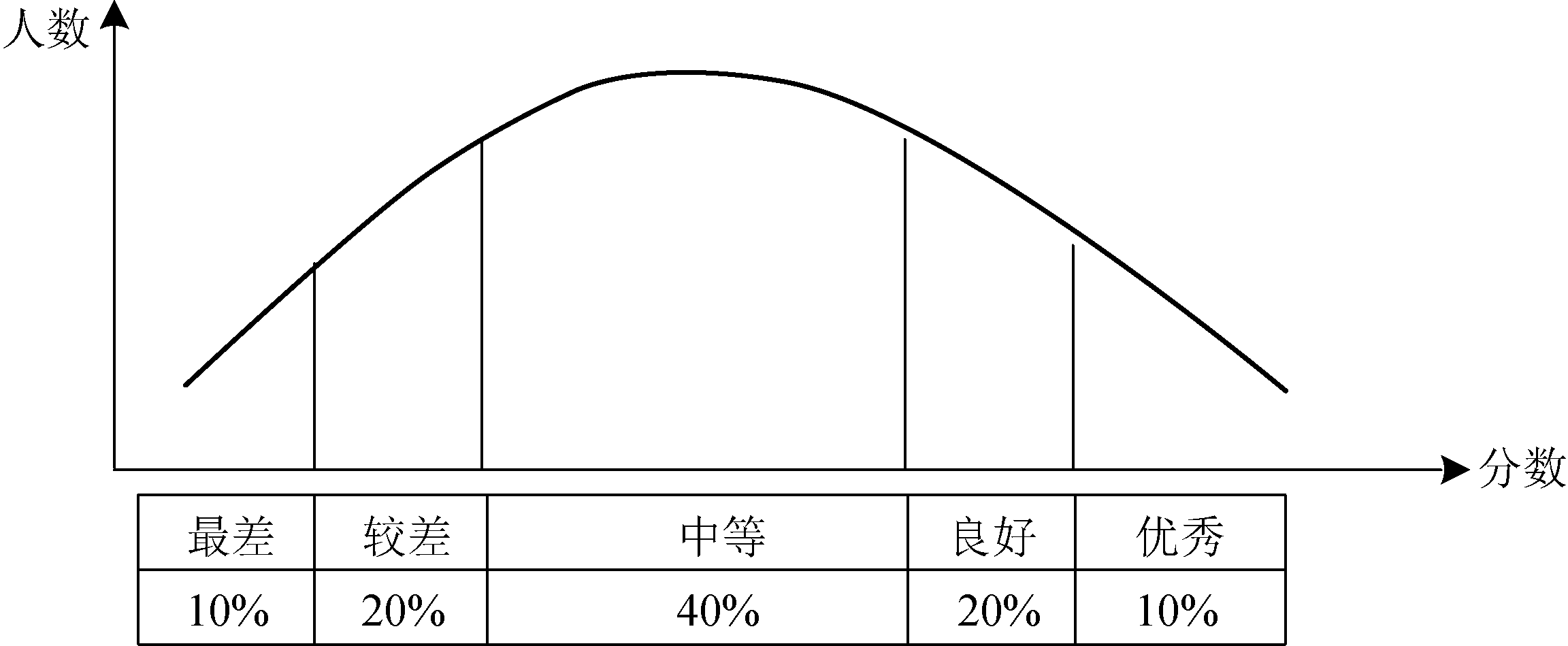
也就是说,大多数(70%)人的成绩要判断3次或3次以上才能成功,假设班级人数为100人,则判定次数为:
100×10%×1+100×20%×2+100×40%×3+100×20%×4+100×10%×5=300(次)
如果我们改写程序为:
1 | if(score <80) |
则判定次数为:
100×10%×3+100×20%×3+100×40%×2+100×20%×2+100×10%×2=230(次)
为什么会有这样大的差别呢?我们来看两种判断方式的树形图,如图2-32所示。
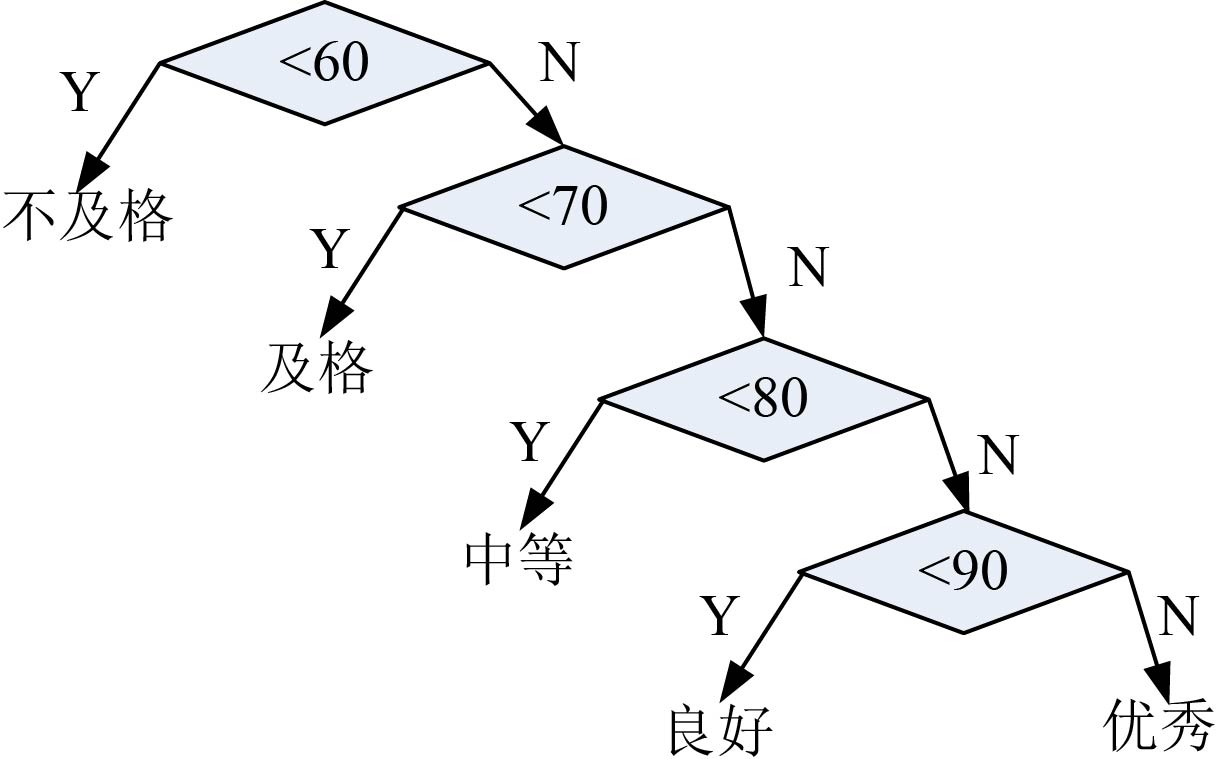
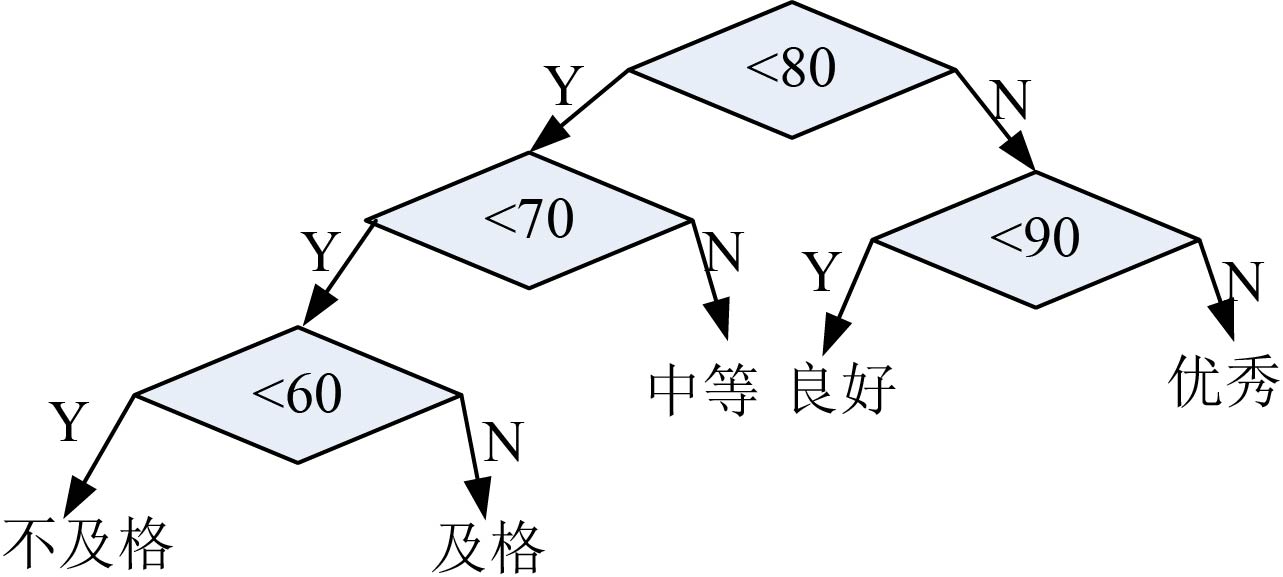
从图2-32中我们可以看到,当频率高的分数越靠近树根(先判断)时,我们只用1次猜中的可能性越大。
再看五笔字型的编码方式:
我们在学习五笔时,需要背一级简码。所谓一级简码,就是指25个汉字,对应着25个按键,打1个字母键再加1个空格键就可打出来相应的字。为什么要这样设置呢?因为根据文字统计,这25个汉字是使用频率最高的。
五笔字根之一级简码:
G 一 F 地 D 在 S 要 A 工
H 上 J 是 K 中 L 国 M 同
T 和 R 的 E 有 W 人 Q 我
Y 主 U 产 I 不 O 为 P 这
N 民 B 了 V 发 C 以 X 经
通常的编码方法有固定长度编码和不等长度编码两种。这是一个设计最优编码方案的问题,目的是使总码长度最短。这个问题利用字符的使用频率来编码,是不等长编码方法,使得经常使用的字符编码较短,不常使用的字符编码较长。如果采用等长的编码方案,假设所有字符的编码都等长,则表示n个不同的字符需要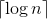 位。例如,3个不同的字符a、b、c,至少需要2位二进制数表示,a为00,b为01,c为10。如果每个字符的使用频率相等,固定长度编码是空间效率最高的方法。
位。例如,3个不同的字符a、b、c,至少需要2位二进制数表示,a为00,b为01,c为10。如果每个字符的使用频率相等,固定长度编码是空间效率最高的方法。
不等长编码方法需要解决两个关键问题:
(1)编码尽可能短
我们可以让使用频率高的字符编码较短,使用频率低的编码较长,这种方法可以提高压缩率,节省空间,也能提高运算和通信速度。即 频率越高,编码越短 。
(2)不能有二义性
例如,ABCD四个字符如果编码如下。
A:0。B:1。C:01。D:10。
那么现在有一列数0110,该怎样翻译呢?是翻译为ABBA,ABD,CBA,还是CD?那么如何消除二义性呢?解决的办法是:任何一个字符的编码不能是另一个字符编码的前缀,即 前缀码特性 。
1952年,数学家D.A.Huffman提出了根据字符在文件中出现的频率,用0、1的数字串表示各字符的最佳编码方式,称为哈夫曼(Huffman)编码。哈夫曼编码很好地解决了上述两个关键问题,被广泛应用于数据压缩,尤其是远距离通信和大容量数据存储方面,常用的JPEG图片就是采用哈夫曼编码压缩的。
2.6.2 算法设计
哈夫曼编码的基本思想是以字符的使用频率作为权构建一棵哈夫曼树,然后利用哈夫曼树对字符进行编码。构造一棵哈夫曼树,是将所要编码的字符作为叶子结点,该字符在文件中的使用频率作为叶子结点的权值,以自底向上的方式,通过n−1次的“合并”运算后构造出的一棵树,核心思想是权值越大的叶子离根越近。
哈夫曼算法采取的 贪心策略是每次从树的集合中取出没有双亲且权值最小的两棵树作为左右子树 ,构造一棵新树,新树根节点的权值为其左右孩子结点权值之和,将新树插入到树的集合中,求解步骤如下。
(1)确定合适的数据结构。编写程序前需要考虑的情况有:
- 哈夫曼树中没有度为1的结点,则一棵有n个叶子结点的哈夫曼树共有2n−1个结点(n−1次的“合并”,每次产生一个新结点),
- 构成哈夫曼树后,为求编码,需从叶子结点出发走一条从叶子到根的路径。
- 译码需要从根出发走一条从根到叶子的路径,那么我们需要知道每个结点的权值、双亲、左孩子、右孩子和结点的信息。
(2)初始化。构造n棵结点为n个字符的单结点树集合T={t1,t2,t3,…,tn},每棵树只有一个带权的根结点,权值为该字符的使用频率。
(3)如果T中只剩下一棵树,则哈夫曼树构造成功,跳到步骤(6)。否则,从集合T中取出没有双亲且权值最小的两棵树ti和tj,将它们合并成一棵新树zk,新树的左孩子为ti,右孩子为tj,zk的权值为ti和tj的权值之和。
(4)从集合T中删去ti,tj,加入zk。
(5)重复以上(3)~(4)步。
(6)约定左分支上的编码为“0”,右分支上的编码为“1”。从叶子结点到根结点逆向求出每个字符的哈夫曼编码,从根结点到叶子结点路径上的字符组成的字符串为该叶子结点的哈夫曼编码。算法结束。
2.6.3 完美图解
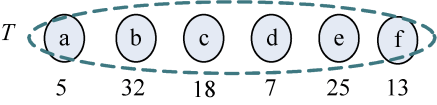
假设我们现在有一些字符和它们的使用频率(见表2-13),如何得到它们的哈夫曼编码呢?
| 字符 | a | b | c | d | e | f |
| :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- | :----- |
| 频率 | 0.05 | 0.32 | 0.18 | 0.07 | 0.25 | 0.13 |
我们可以把每一个字符作为叶子,它们对应的频率作为其权值,为了比较大小方便,可以对其同时扩大100倍,得到a~f分别对应5、32、18、7、25、13。
(1)初始化。构造n棵结点为n个字符的单结点树集合T={a,b,c,d,e,f},如图2-33所示。
(2)从集合T中取出没有双亲的且权值最小的两棵树a和d,将它们合并成一棵新树t1,新树的左孩子为a,右孩子为d,新树的权值为a和d的权值之和为12。新树的树根t1加入集合T,a和d从集合T中删除,如图2-34所示。
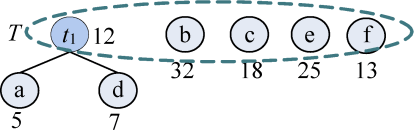
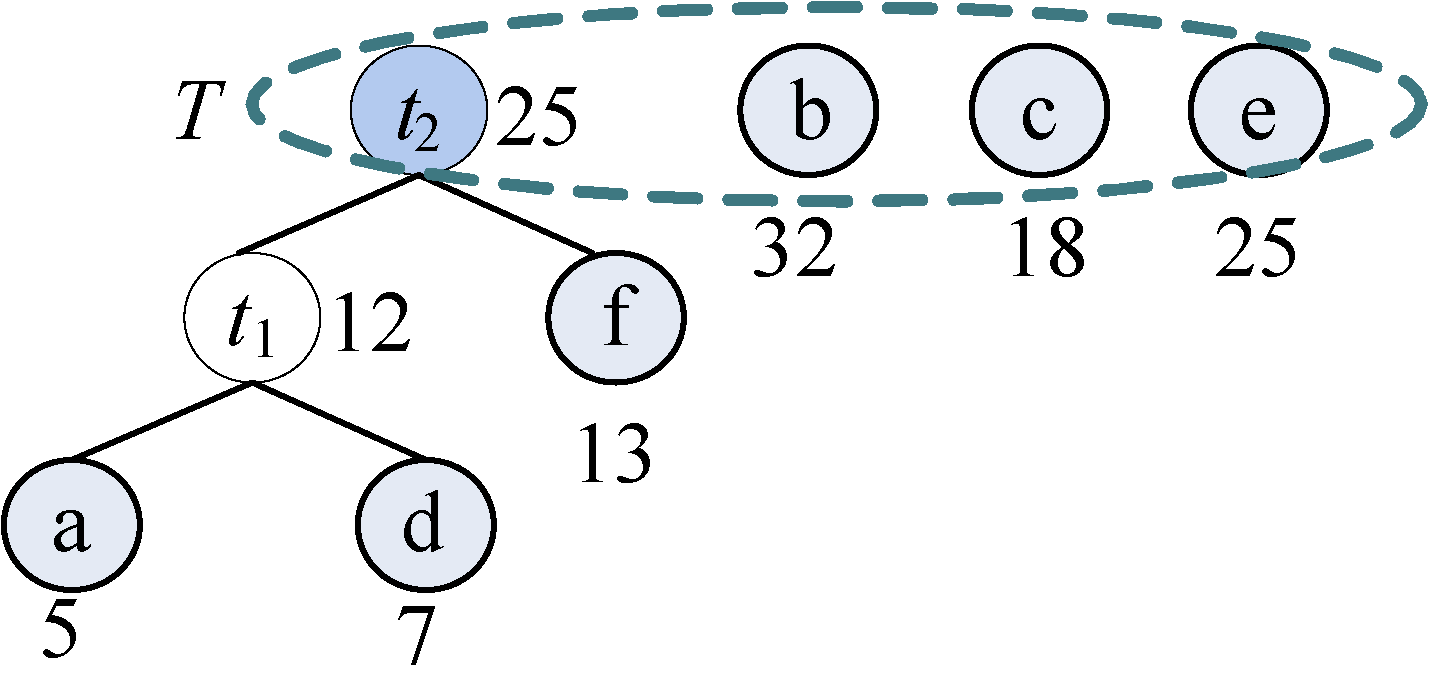
(3)从集合T中取出没有双亲的且权值最小的两棵树t1和f,将它们合并成一棵新树t2,新树的左孩子为t1,右孩子为f,新树的权值为t1和f的权值之和为25。新树的树根t2加入集合T,将t1和f从集合T中删除,如图2-35所示。
(4)从集合T中取出没有双亲且权值最小的两棵树c和e,将它们合并成一棵新树t3,新树的左孩子为c,右孩子为e,新树的权值为c和e的权值之和为43。新树的树根t3加入集合T,将c和e从集合T中删除,如图2-36所示。
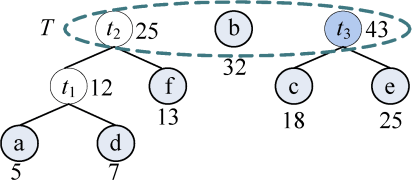
(5)从集合T中取出没有双亲且权值最小的两棵树t2和b,将它们合并成一棵新树t4,新树的左孩子为t2,右孩子为b,新树的权值为t2和b的权值之和为57。新树的树根t4加入集合T,将t2和b从集合T中删除,如图2-37所示。
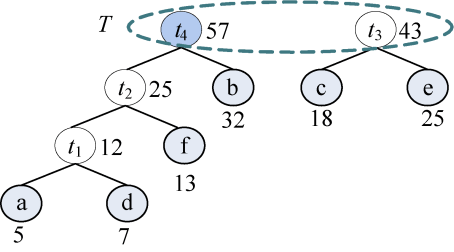
(6)从集合T中取出没有双亲且权值最小的两棵树t3和t4,将它们合并成一棵新树t5,新树的左孩子为t4,右孩子为t3,新树的权值为t3和t4的权值之和为 100。新树的树根t5加入集合T,将t3和t4从集合T中删除,如图 2-38所示。
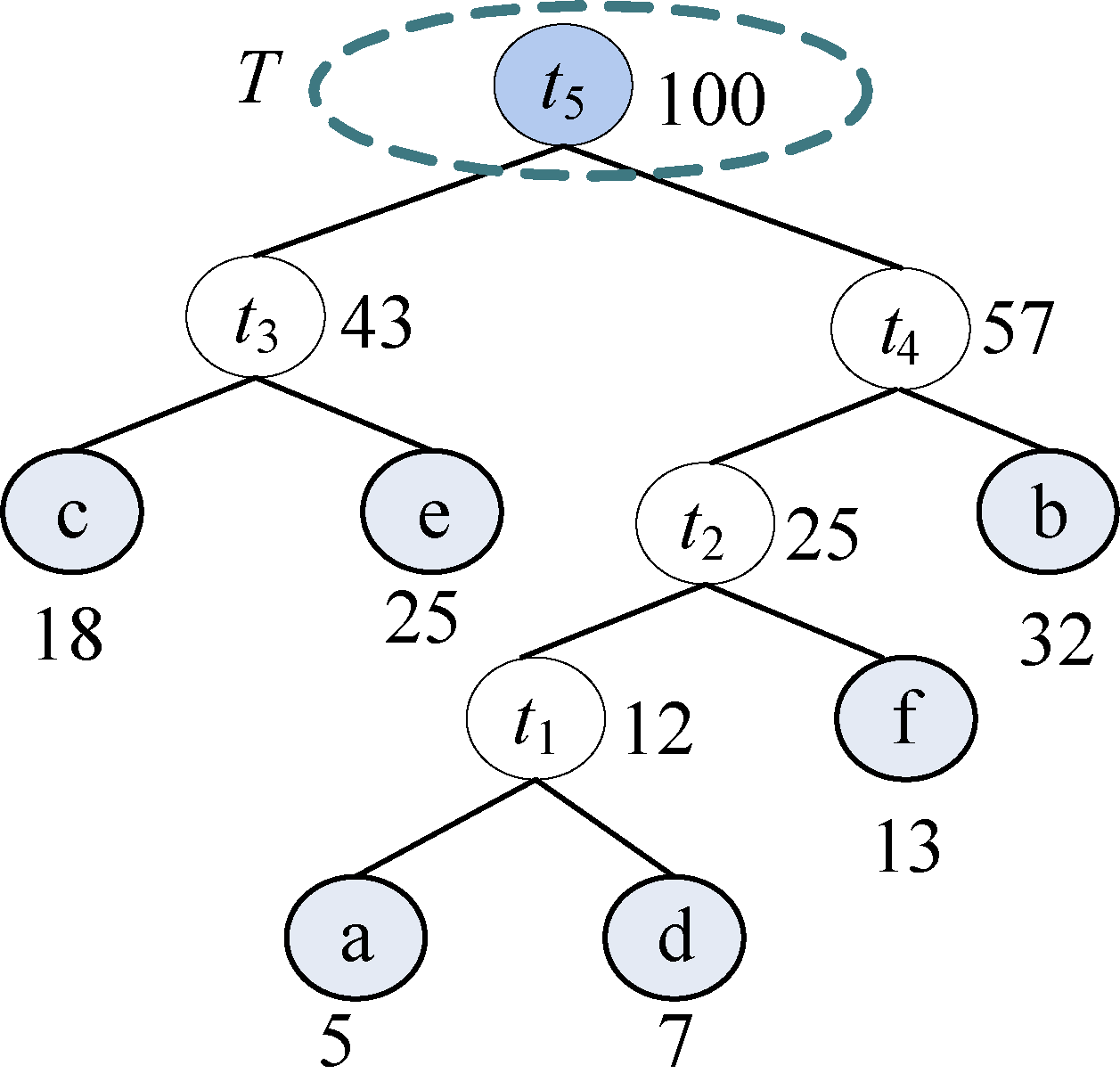
(7)T中只剩下一棵树,哈夫曼树构造成功。
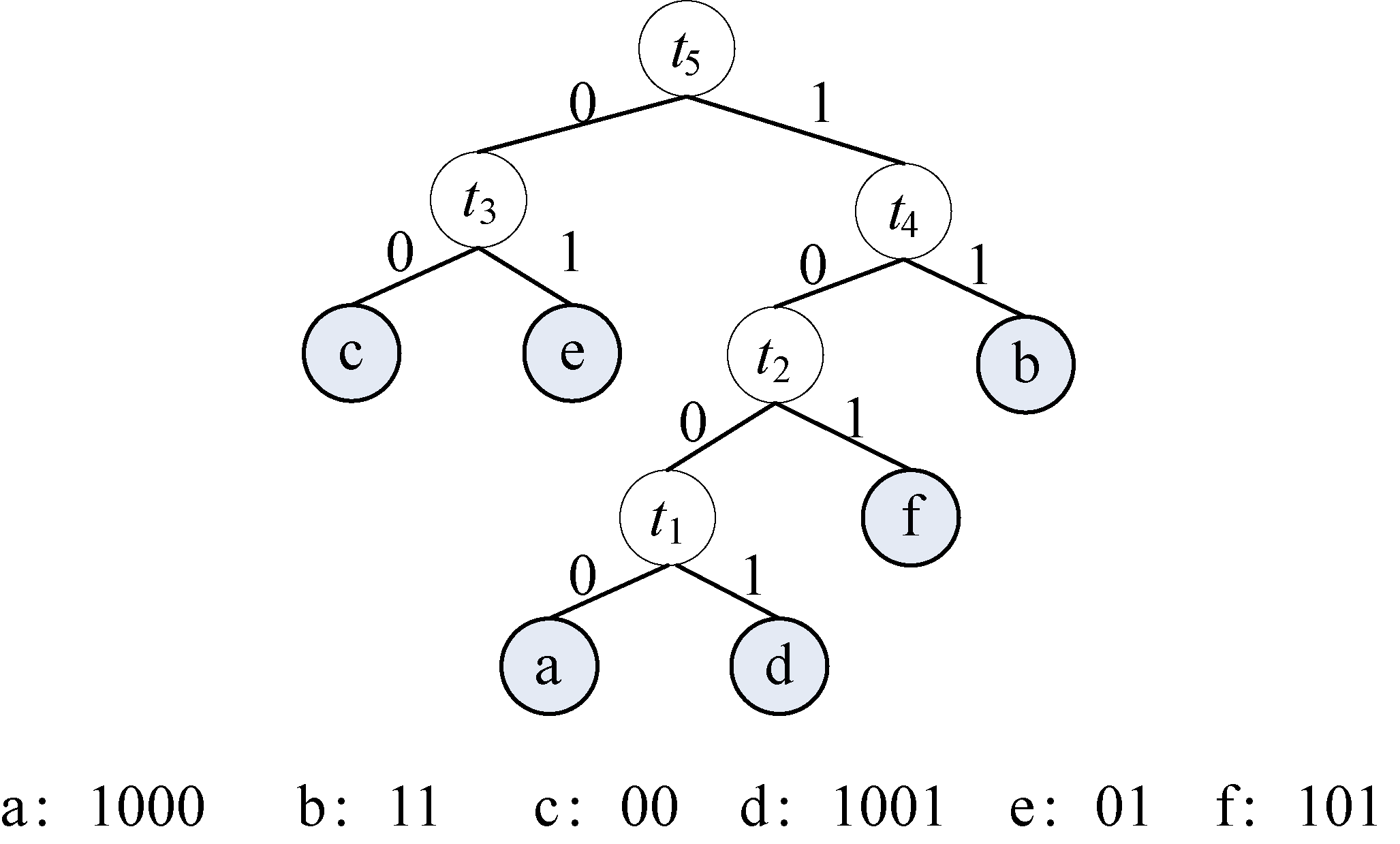
(8)约定左分支上的编码为“0”,右分支上的编码为“1”。从叶子结点到根结点逆向求出每个字符的哈夫曼编码,从根结点到叶子结点路径上的字符组成的字符串为该叶子结点的哈夫曼编码,如图2-39所示。
2.6.4 伪代码详解
在构造哈夫曼树的过程中,首先给每个结点的双亲、左孩子、右孩子初始化为−1,找出所有结点中双亲为−1、权值最小的两个结点t1、t2,并合并为一棵二叉树,更新信息(双亲结点的权值为t1、t2权值之和,其左孩子为权值最小的结点t1,右孩子为次小的结点t2,t1、t2的双亲为双亲结点的编号)。重复此过程,构造一棵哈夫曼树。
(1)数据结构
每个结点的结构包括权值、双亲、左孩子、右孩子、结点字符信息这 5 个域。如图 2-40所示,定义为结构体形式,定义结点结构体HnodeType:
1 | typedef struct |

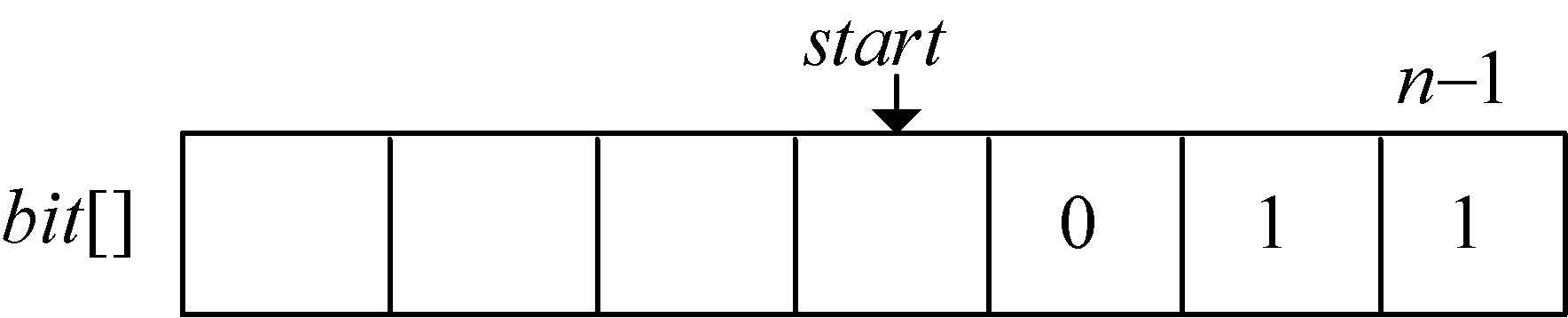
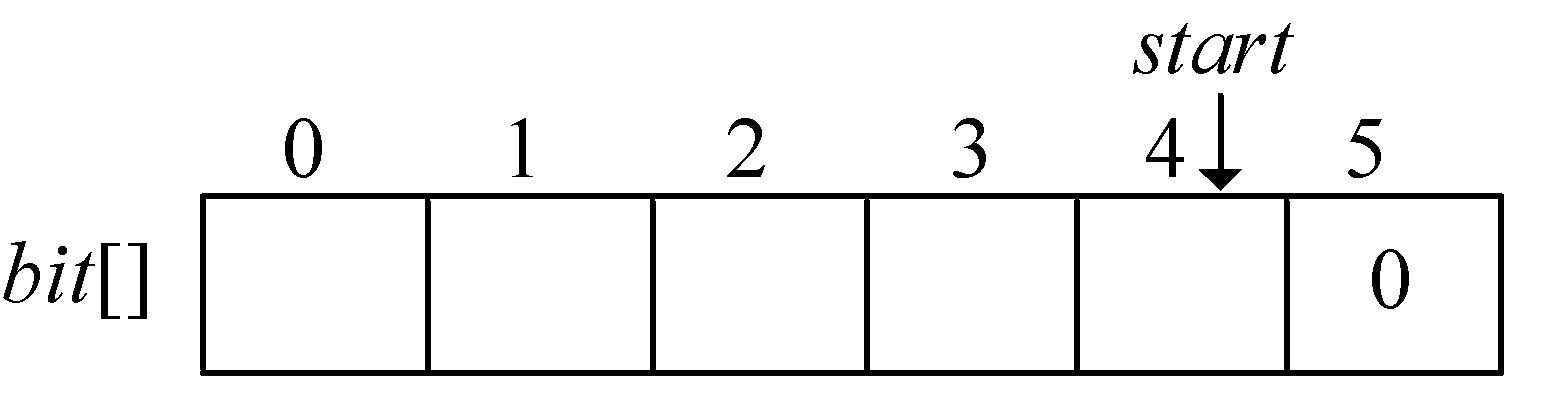
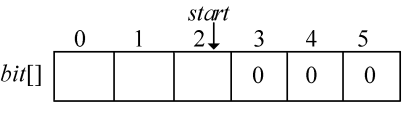
在编码结构体中,bit[]存放结点的编码,start 记录编码开始下标,逆向译码(从叶子到根,想一想为什么不从根到叶子呢?)。存储时,start从n−1开始依次递减,从后向前存储;读取时,从start+1开始到n−1,从前向后输出,即为该字符的编码。如图2-41所示。
编码结构体HcodeType:
1 | typedef struct |
(2)初始化
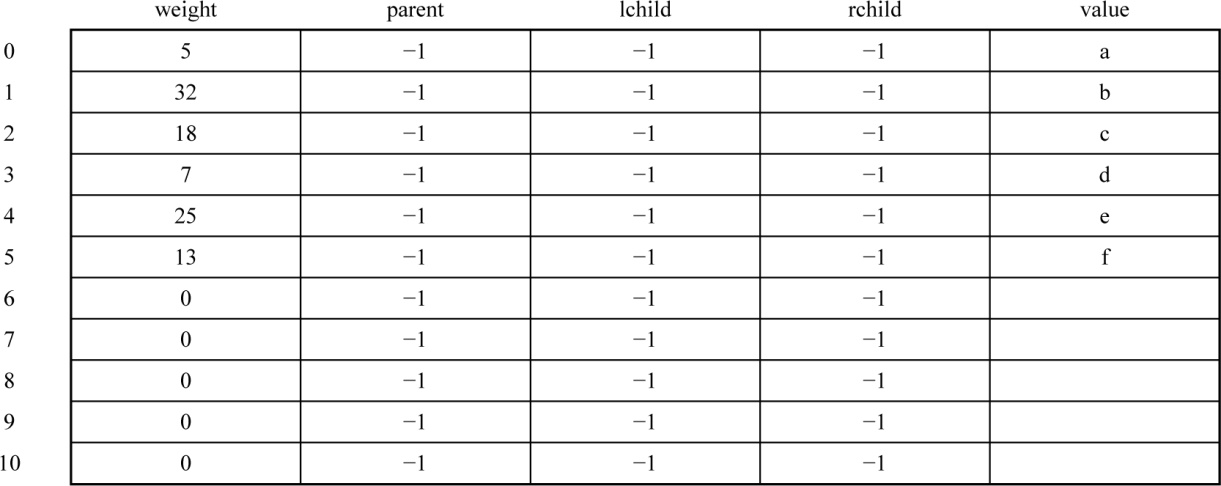
初始化存放哈夫曼树数组HuffNode[]中的结点(见表2-14):
1 | for (i=0; i<2*n-1; i++){ |
输入n个叶子结点的字符及权值:
1 | for (i=0; i<n; i++){ |
(3)循环构造Huffman树
从集合T中取出双亲为−1且权值最小的两棵树ti和tj,将它们合并成一棵新树zk,新树的左儿子为ti,右孩子为tj,zk的权值为ti和tj的权值之和。
1 | int i, j, x1, x2; //x1、x2为两个最小权值结点的序号。 |
图解:
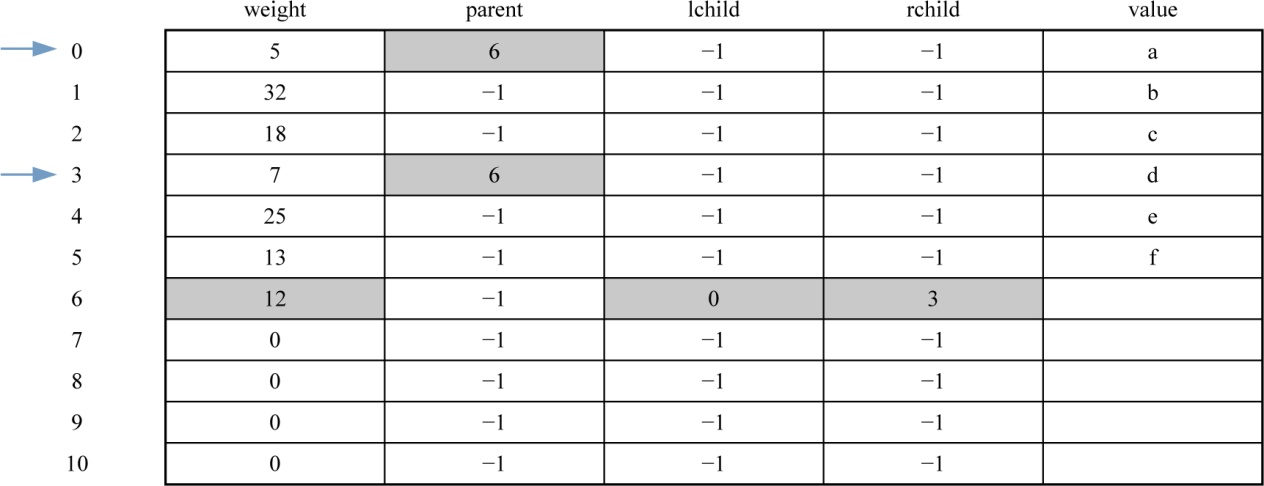
(1)i=0时,j=0;j<6;找双亲为−1,权值最小的两个数:
1 | x1=0 x2=3;//x1、x2为两个最小权值结点的序号 |
数据更新后如表2-15所示。
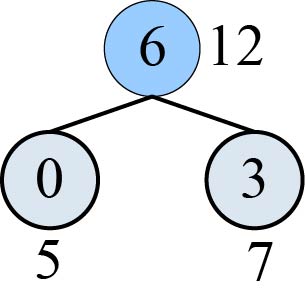
对应的哈夫曼树如图2-42所示。
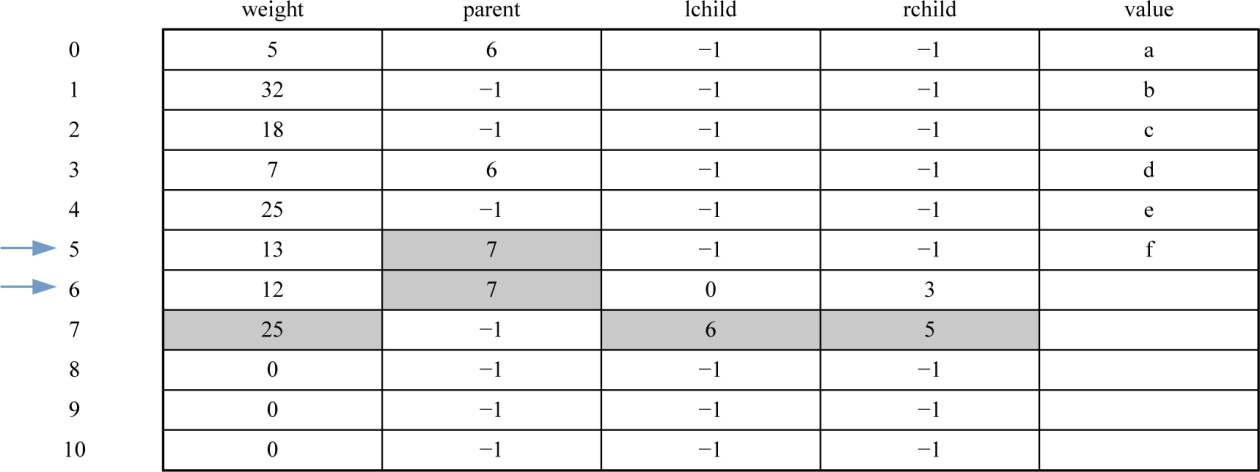
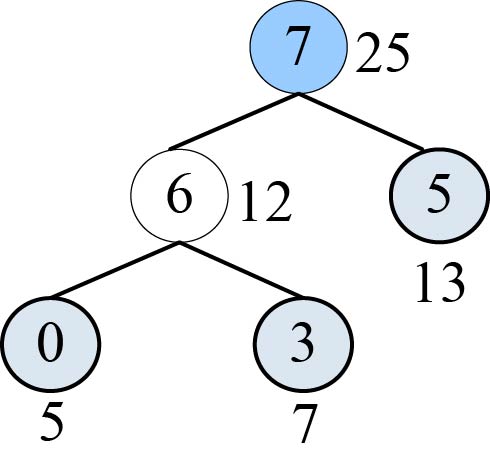
(2)i=1时,j=0;j<7;找双亲为−1,权值最小的两个数:
1 | x1=6 x2=5;//x1、x2为两个最小权值结点的序号 |
数据更新后如表2-16所示。
对应的哈夫曼树如图2-43所示。
(3)i=2时,j=0;j<8;找双亲为−1,权值最小的两个数:
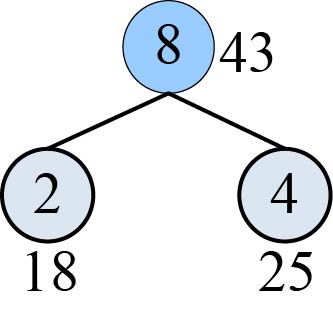
1 | x1=2 x2=4;//x1、x2为两个最小权值结点的序号 |
数据更新后如表2-17所示。
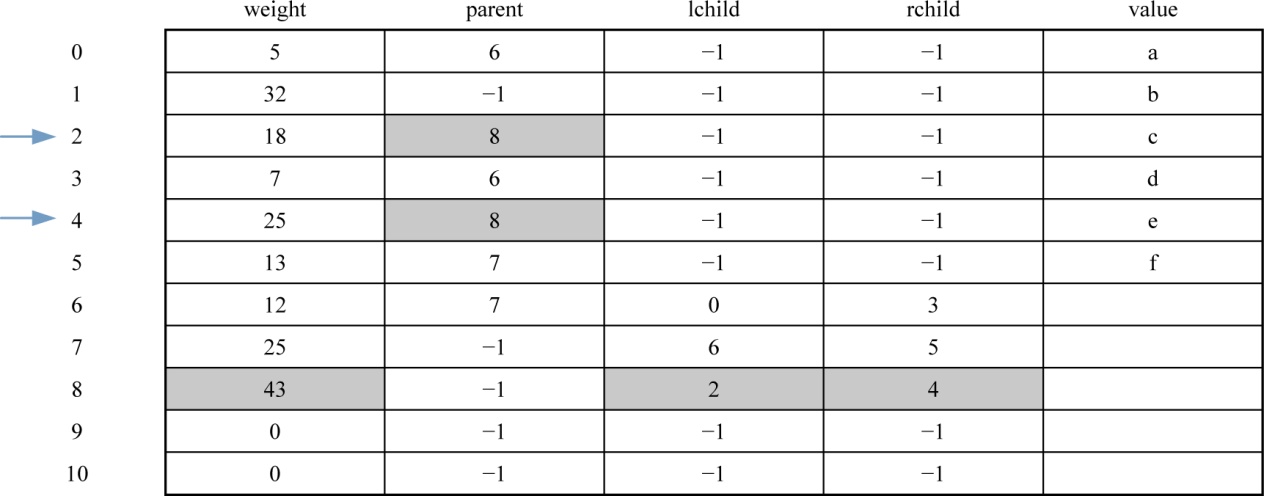
对应的哈夫曼树如图2-44所示。
(4)i=3时,j=0;j<9;找双亲为−1,权值最小的两个数:
1 | x1=7 x2=1;//x1、x2为两个最小权值结点的序号 |
数据更新后如表2-18所示。
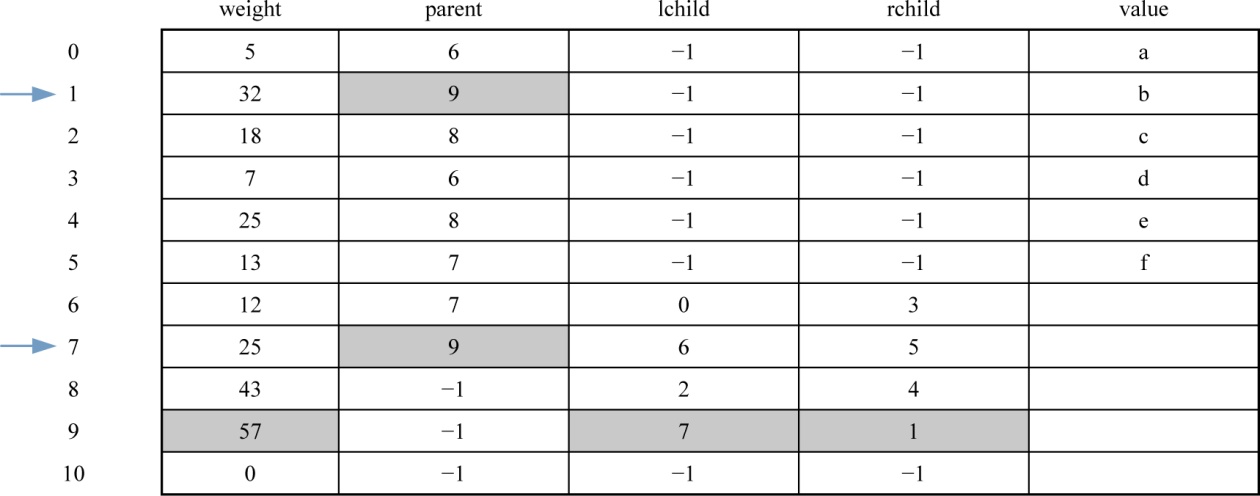
对应的哈夫曼树如图2-45所示。

(5)i=4时,j=0;j<10;找双亲为−1,权值最小的两个数:
1 | x1=8 x2=9;//x1、x2为两个最小权值结点的序号 |
数据更新后如表2-19所示。
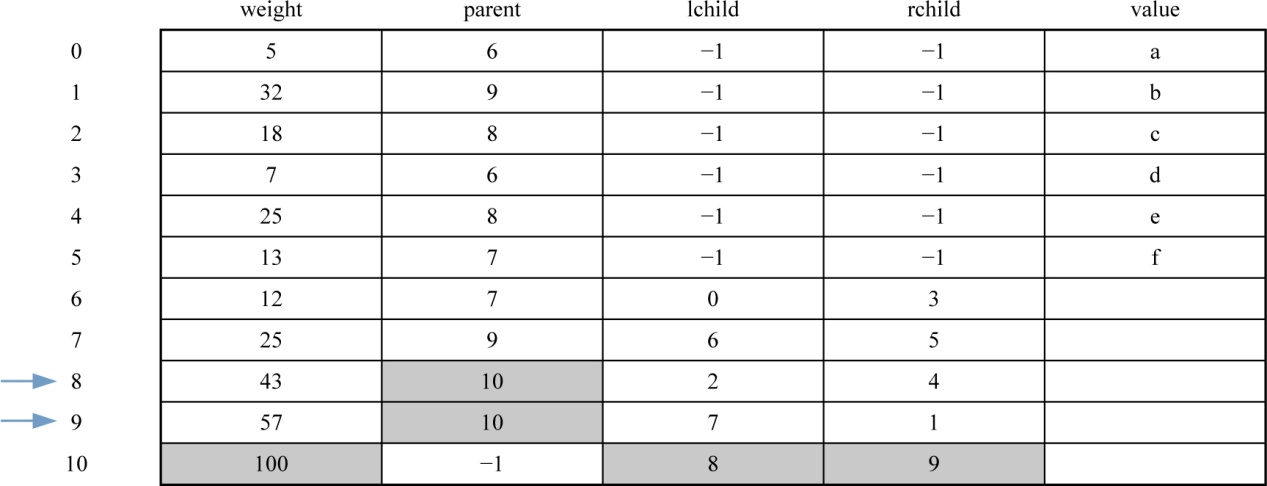
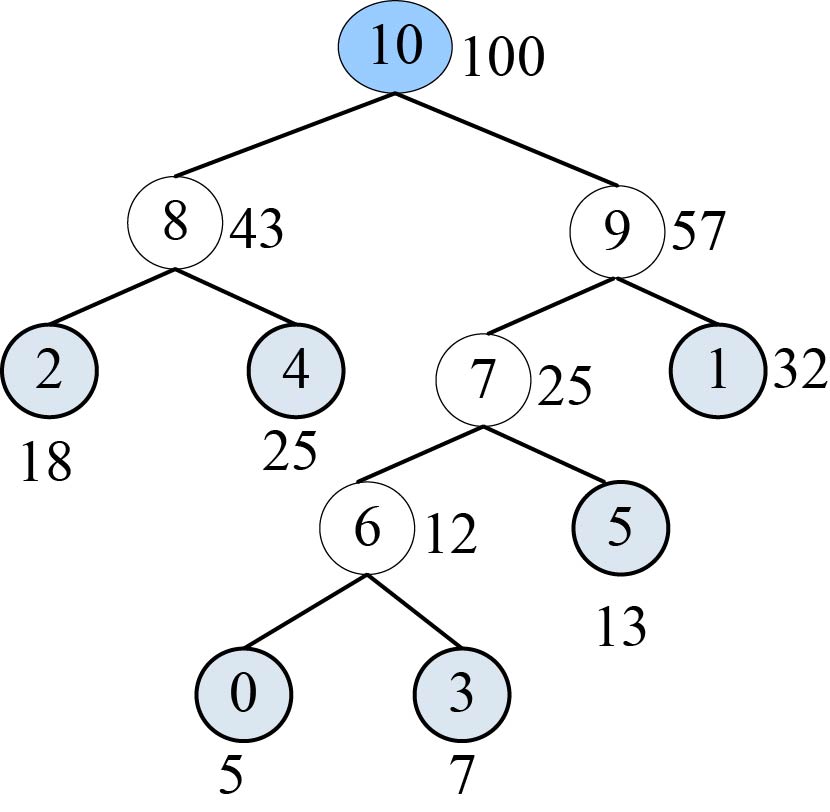
对应的哈夫曼树如图2-46所示。
(6)输出哈夫曼编码
1 | void HuffmanCode(HCodeType HuffCode[MAXLEAF], int n) |
图解:哈夫曼编码数组如图2-47所示。
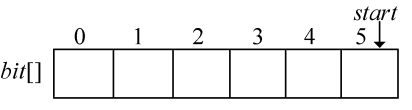
(1)i=0时,c=0;
1 | cd.start = n-1=5; |
构建完成的哈夫曼树数组如表2-20所示。
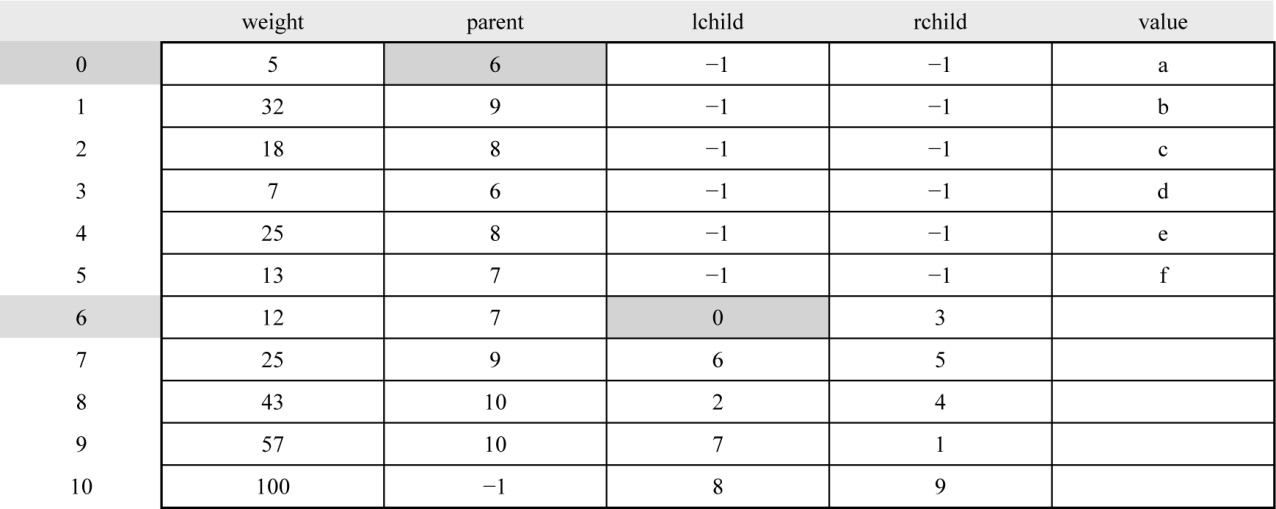
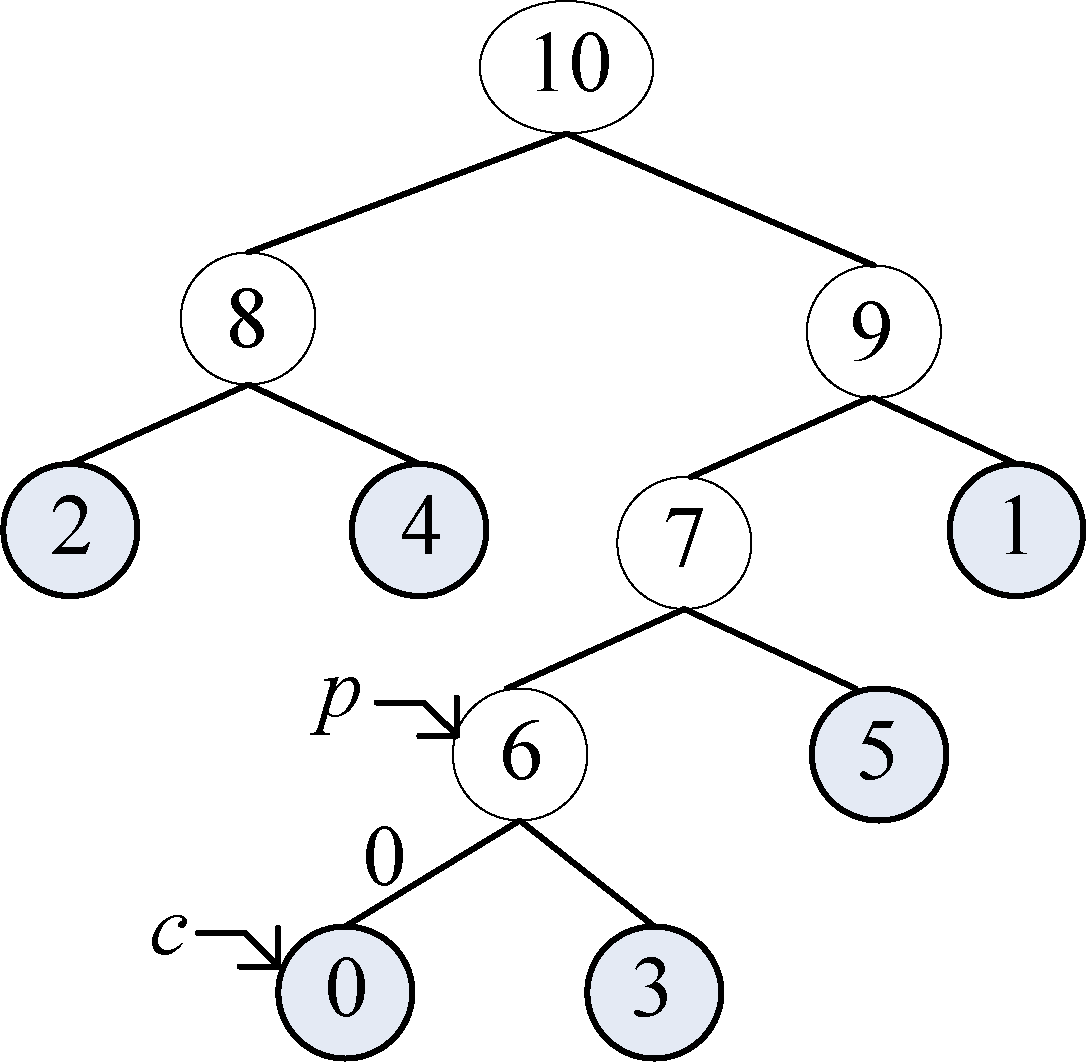
如果p != −1,那么从表HuffNode[]中读出6号结点的左孩子和右孩子,判断0号结点是它的左孩子还是右孩子,如果是左孩子编码为0;如果是右孩子编码为1。
从表2-20可以看出:
1 | HuffNode[6].lchild=0;//0号结点是其父亲6号的左孩子 |
哈夫曼编码树如图2-48所示,哈夫曼编码数组如图2-49所示。
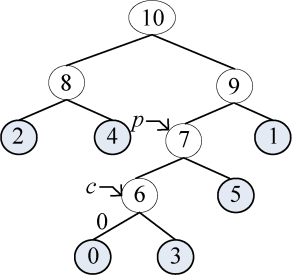
1 | c = p=6; /* c、p变量上移,准备下一循环 */ |
c、p变量上移后如图2-50所示。
1 | p != -1; |
哈夫曼编码树如图2-51所示,哈夫曼编码数组如图2-52所示。
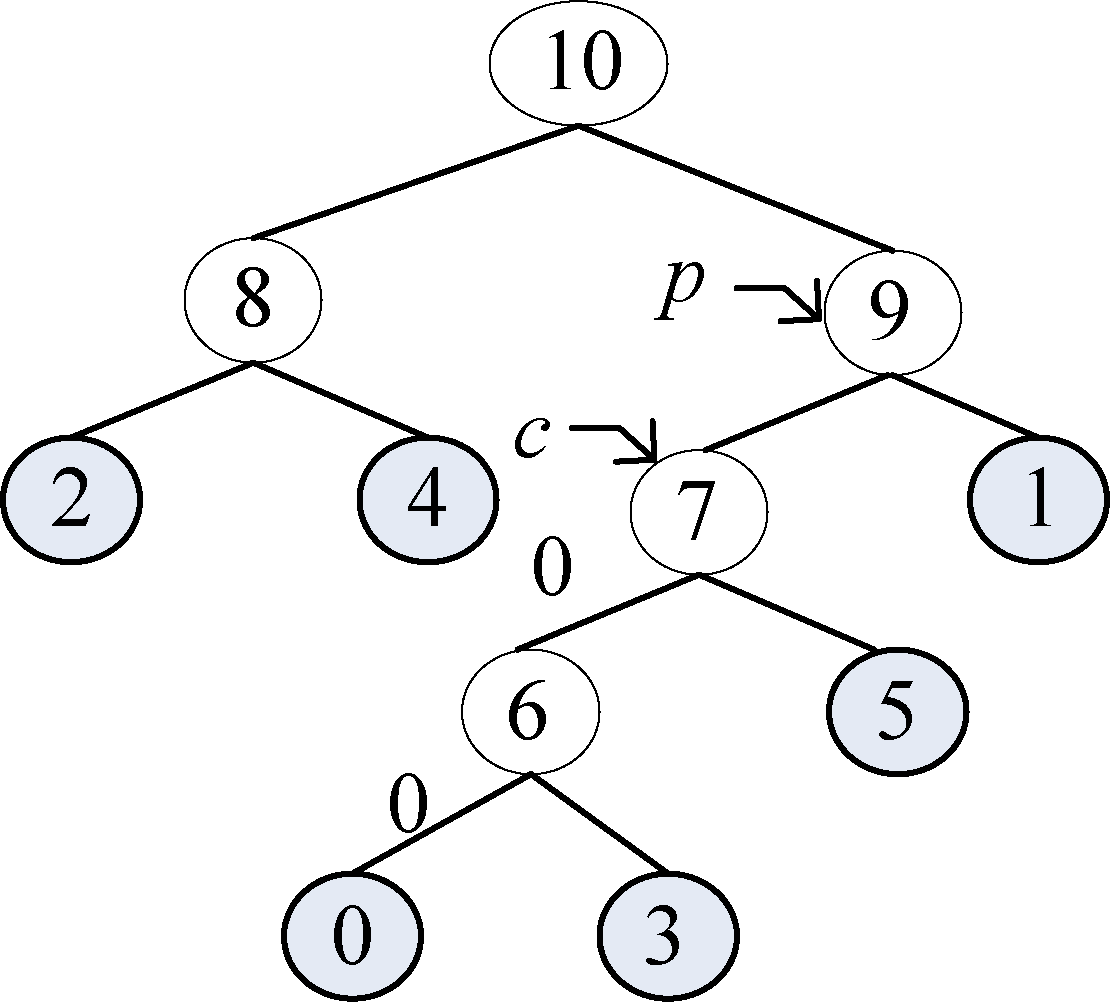
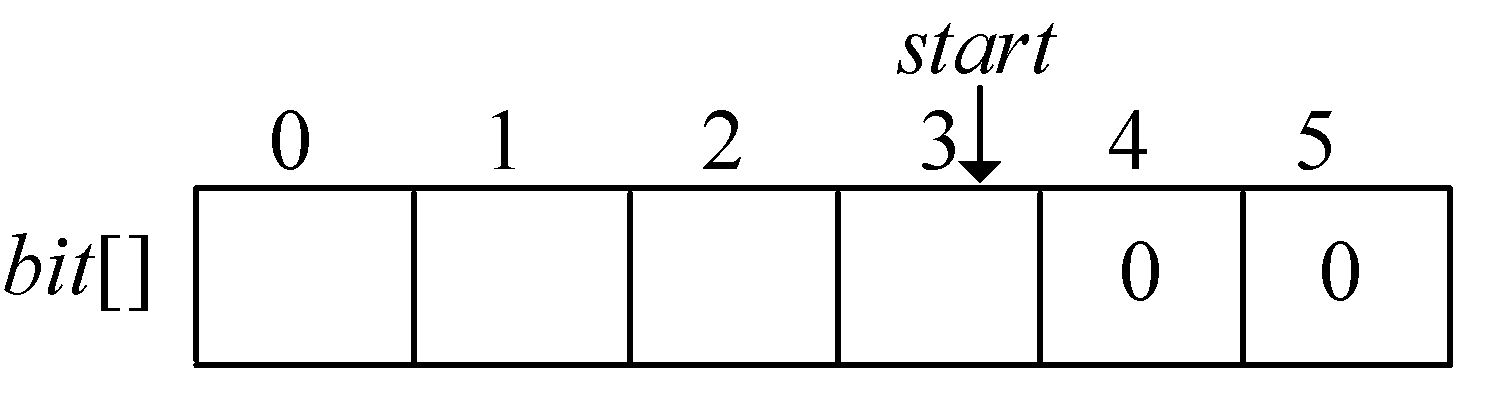
1 | p != -1; |
哈夫曼编码树如图2-53所示,哈夫曼编码数组如图2-54所示。
1 | p != -1; |
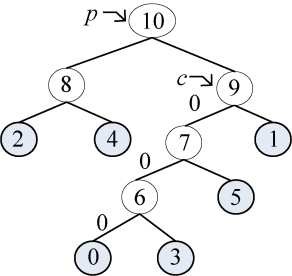
哈夫曼编码树如图2-55所示,哈夫曼编码数组如图2-56所示。
1 | p = -1;该叶子结点编码结束。 |
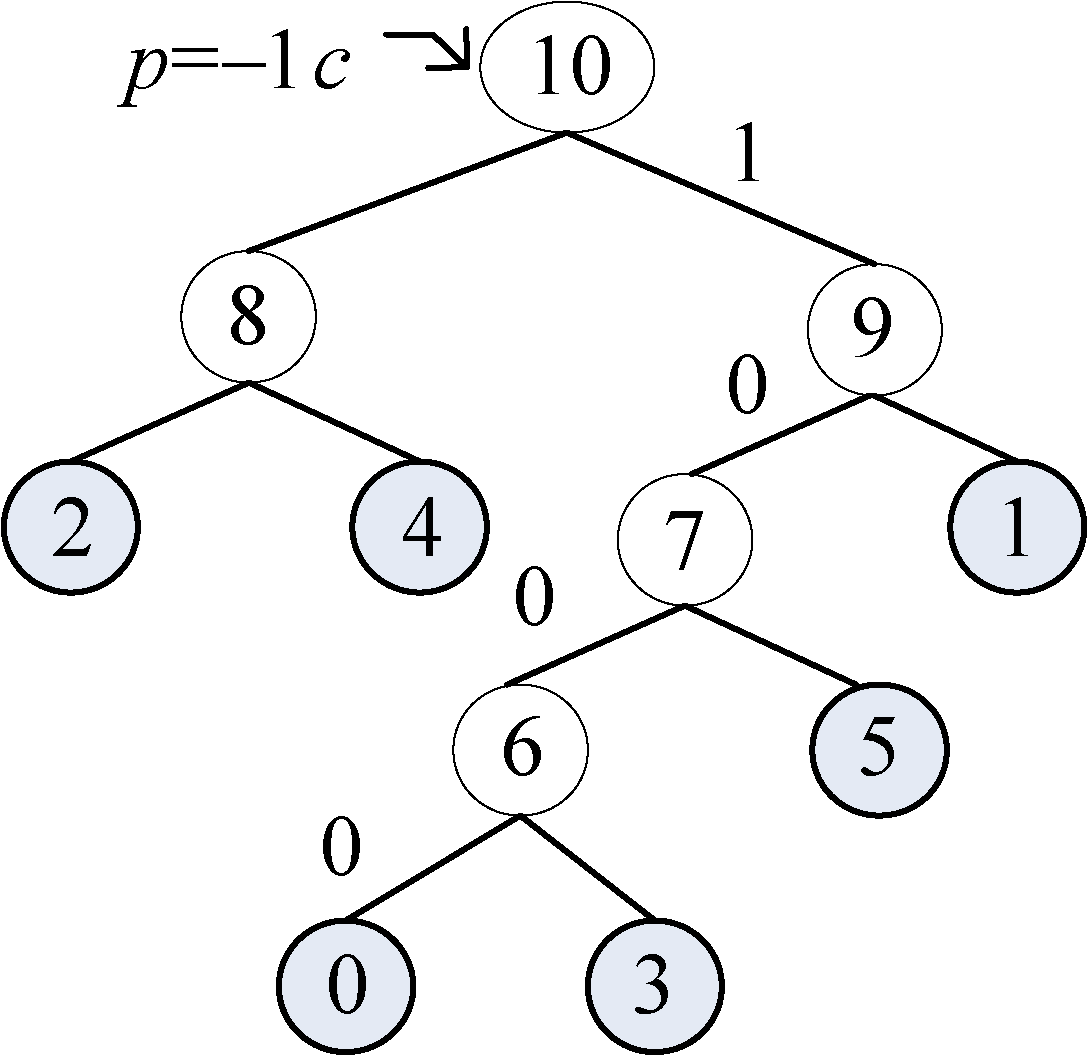
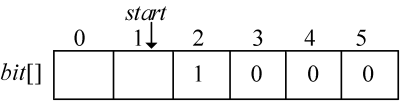
HuffCode[]数组如图2-57所示。
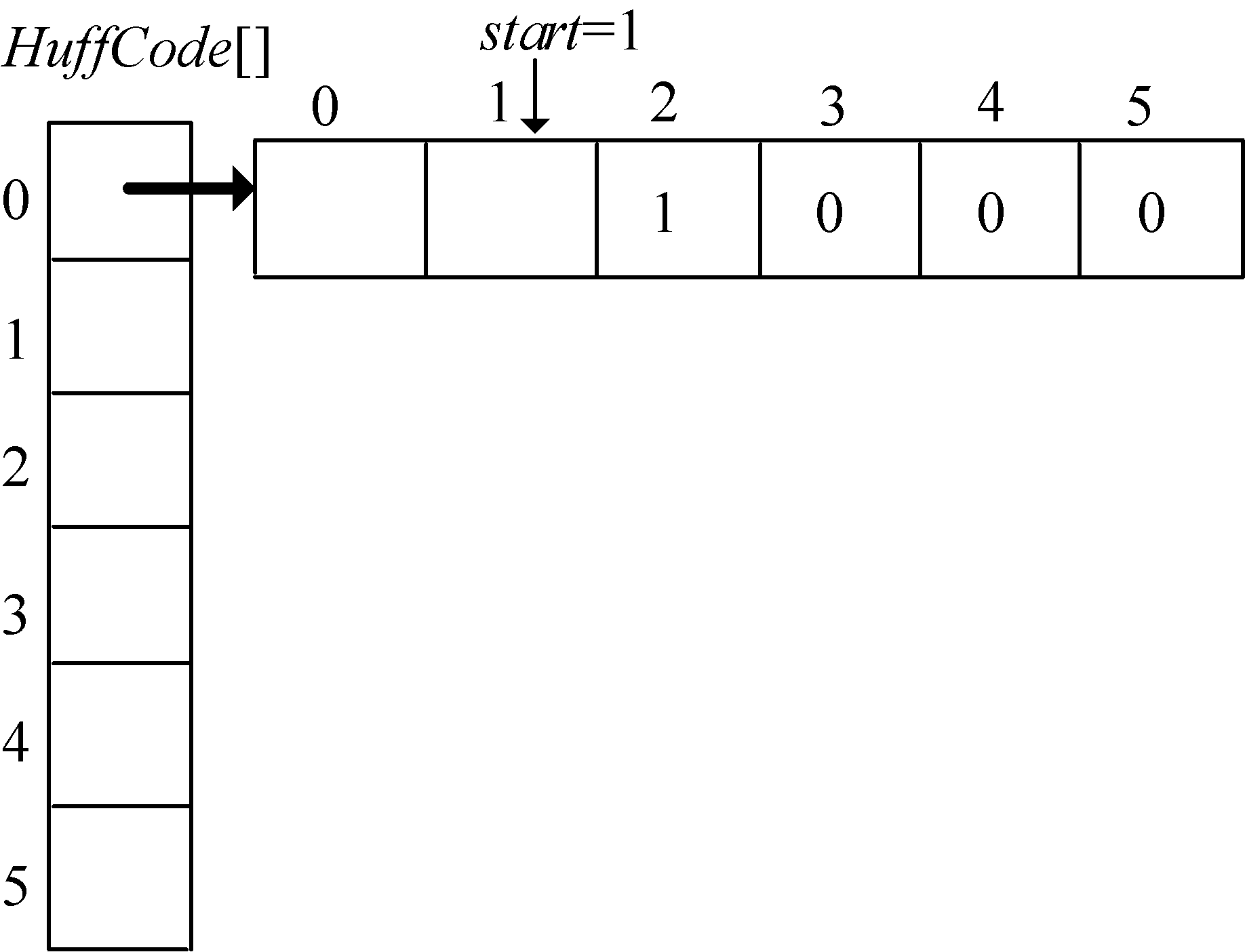
注意:图中的箭头不表示指针。
2.6.5 实战演练
1 | //program 2-6 |
算法实现和测试
(1)运行环境
Code::Blocks
(2)输入
1 | Please input n: |
(3)输出
1 | x1.weight and x2.weight in round 1 0.05 0.07 |
2.6.6 算法解析及优化拓展
1.算法复杂度分析
(1)时间复杂度:由程序可以看出,在函数HuffmanTree()中,if (HuffNode[j].weight<m1&& HuffNode[j].parent==−1)为基本语句,外层i与j组成双层循环:
i=0时,该语句执行n次;
i=1时,该语句执行n+1次;
i=2时,该语句执行n+2次;
……
i=n−2时,该语句执行n+n−2次;
则基本语句共执行n+(n+1)+(n+2)+…+(n+(n−2))=(n−1)*(3n−2)/2次(等差数列);在函数HuffmanCode()中,编码和输出编码时间复杂度都接近n2;则该算法时间复杂度为O(n2)。
(2)空间复杂度:所需存储空间为结点结构体数组与编码结构体数组,哈夫曼树数组 HuffNode[]中的结点为n个,每个结点包含bit[MAXBIT]和start两个域,则该算法空间复杂度为O( n* MAXBIT)。
2.算法优化拓展
该算法可以从两个方面优化:
(1)函数HuffmanTree()中找两个权值最小结点时使用优先队列,时间复杂度为logn,执行n−1次,总时间复杂度为O( n logn)。
(2)函数HuffmanCode()中,哈夫曼编码数组HuffNode[]中可以定义一个动态分配空间的线性表来存储编码,每个线性表的长度为实际的编码长度,这样可以大大节省空间。
2.7 沟通无限校园网——最小生成树
校园网是为学校师生提供资源共享、信息交流和协同工作的计算机网络。校园网是一个宽带、具有交互功能和专业性很强的局域网络。如果一所学校包括多个学院及部门,也可以形成多个局域网络,并通过有线或无线方式连接起来。原来的网络系统只局限于以学院、图书馆为单位的局域网,不能形成集中管理以及各种资源的共享,个别学院还远离大学本部,这些情况严重地阻碍了整个学校的网络化需求。现在需要设计网络电缆布线,将各个单位的局域网络连通起来,如何设计能够使费用最少呢?

2.7.1 问题分析
某学校下设10个学院,3个研究所,1个大型图书馆,4个实验室。其中,1~10号节点代表10个学院,11~13号节点代表3个研究所,14号节点代表图书馆,15~18号节点代表4个实验室。该问题用无向连通图G =(V,E)来表示通信网络,V表示顶点集,E表示边集。把各个单位抽象为图中的顶点,顶点与顶点之间的边表示单位之间的通信网络,边的权值表示布线的费用。如果两个节点之间没有连线,代表这两个单位之间不能布线,费用为无穷大。如图2-59所示。
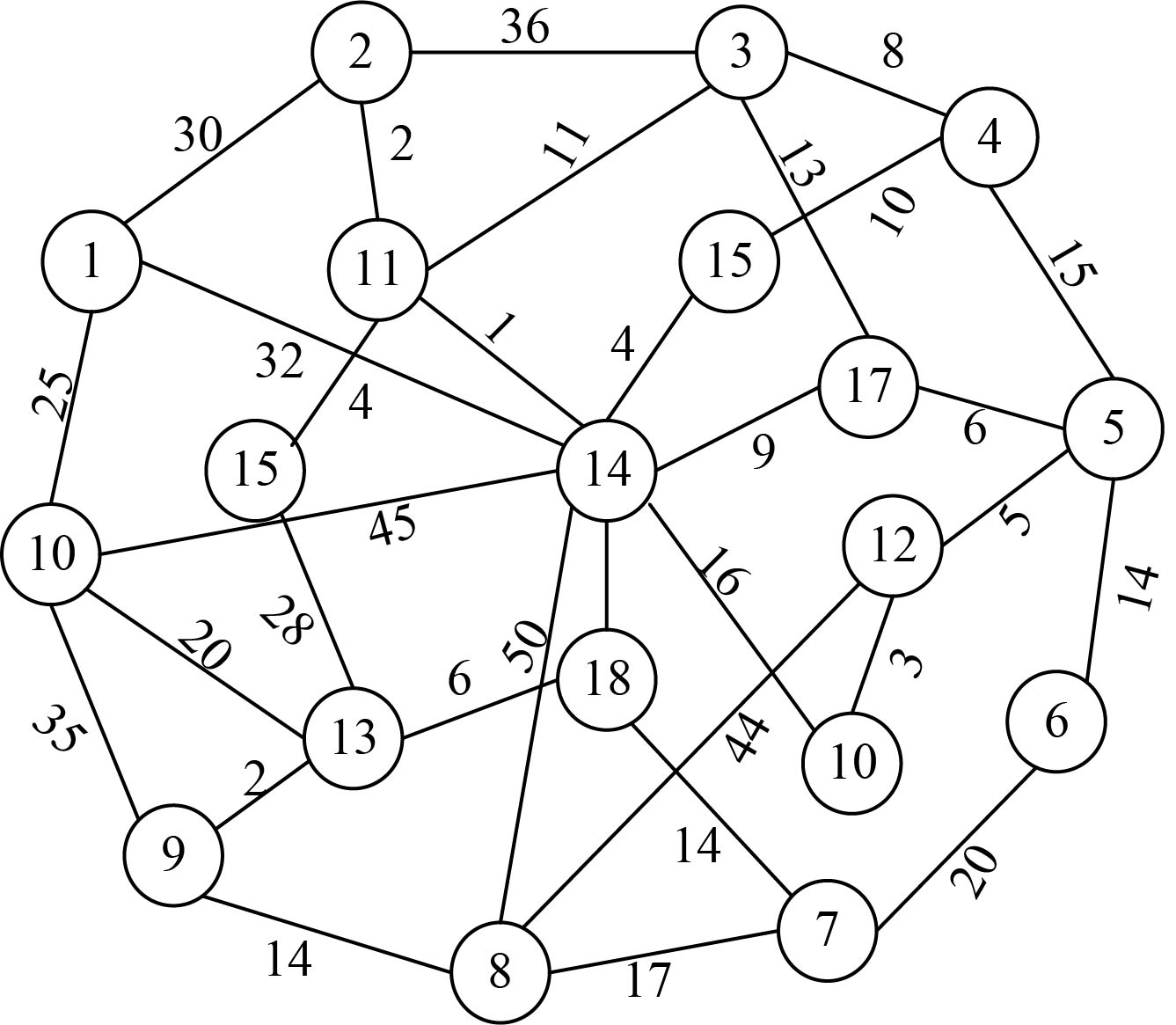
那么我们如何设计网络电缆布线,将各个单位连通起来,并且费用最少呢?
对于n个顶点的连通图,只需n−1条边就可以使这个图连通,n−1条边要想保证图连通,就必须不含回路,所以我们只需要找出n−1条权值最小且无回路的边即可。
需要说明几个概念。
(1)子图:从原图中选中一些顶点和边组成的图,称为原图的子图。
(2)生成子图:选中一些边和所有顶点组成的图,称为原图的生成子图。
(3)生成树:如果生成子图恰好是一棵树,则称为生成树。
(4)最小生成树:权值之和最小的生成树,则称为最小生成树。
本题就是最小生成树求解问题。
2.7.2 算法设计
找出n−1条权值最小的边很容易,那么怎么保证无回路呢?
如果在一个图中深度搜索或广度搜索有没有回路,是一件繁重的工作。有一个很好的办法—— 避圈法 。在生成树的过程中,我们把已经在生成树中的结点看作一个集合,把剩下的结点看作另一个集合,从连接两个集合的边中选择一条权值最小的边即可。
首先任选一个结点,例如1号结点,把它放在集合U中,U={1},那么剩下的结点即V−U={2,3,4,5,6,7},V是图的所有顶点集合。如图2-60所示。
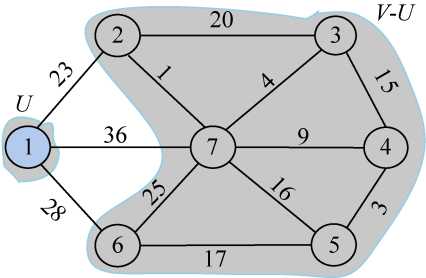
现在只需在连接两个集合(V和V−U)的边中看哪一条边权值最小,把权值最小的边关联的结点加入到集合U。从图2-68可以看出,连接两个集合的3条边中,结点1到结点2的边权值最小,选中此条边,把2号结点加入U集合U={1,2},V−U={3,4,5,6,7}。
再从连接两个集合(V和V−U)的边中选择一条权值最小的边。从图2-61可以看出,连接两个集合的4条边中,结点2到结点7的边权值最小,选中此条边,把7号结点加入U集合U={1,2,7},V−U={3,4,5,6}。
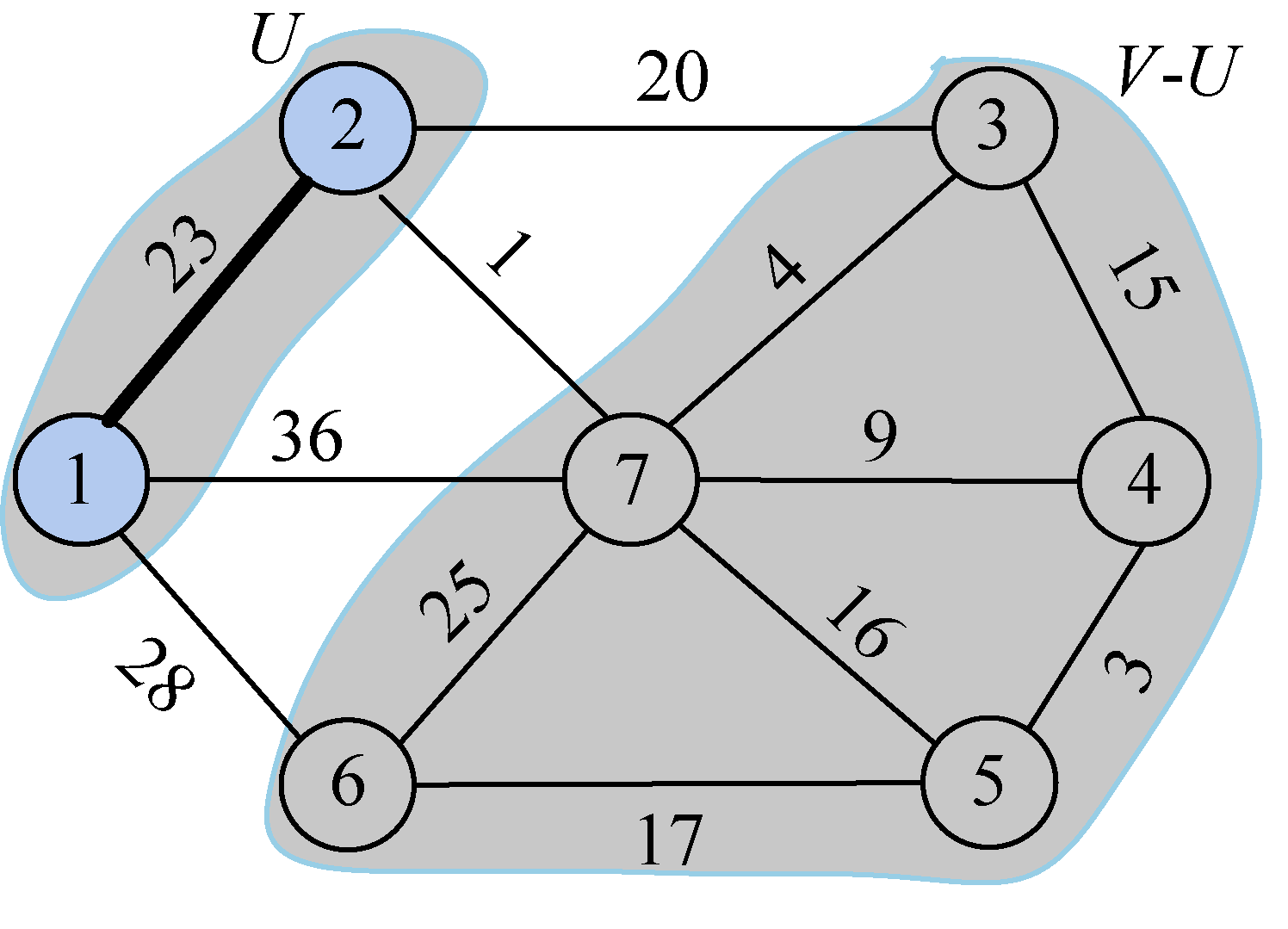
如此下去,直到U=V结束,选中的边和所有的结点组成的图就是最小生成树。
是不是非常简单啊?
这就是Prim算法,1957年由美国计算机科学家Robert C.Prim发现的。那么如何用算法来实现呢?
首先,令U={u0},u0∈V,TE={}。u0可以是任何一个结点,因为最小生成树包含所有结点,所以从哪个结点出发都可以得到最小生成树,不影响最终结果。TE为选中的边集。
然后,做如下 贪心选择 :选取连接U和V−U的所有边中的最短边,即满足条件i∈U,j∈V−U,且边(i,j)是连接U和V−U的所有边中的最短边,即该边的权值最小。
然后,将顶点j加入集合U,边(i,j)加入TE。继续上面的贪心选择一直进行到U=V为止,此时,选取到的所有边恰好构成图G的一棵最小生成树T。
算法设计及步骤如下。
步骤1:确定合适的数据结构。设置带权邻接矩阵C存储图G,如果图G中存在边(u,x),令C[u][x]等于边(u,x)上的权值,否则,C[u][x]=∞;bool数组s[],如果s[i]=true,说明顶点i已加入集合U。
如图2-62所示,直观地看图很容易找出 U 集合到 V−U集合的边中哪条边是最小的,但是程序中如果穷举这些边,再找最小值就太麻烦了,那怎么办呢?
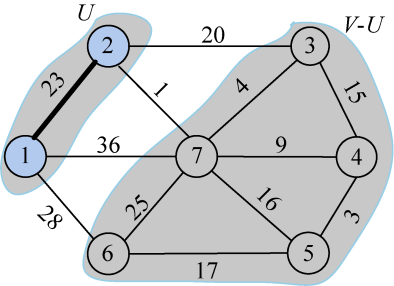
可以通过设置两个数组巧妙地解决这个问题,closest[j]表示V−U中的顶点j到集合U中的最邻近点,lowcost[j]表示V−U中的顶点j到集合U中的最邻近点的边值,即边(j,closest[j])的权值。
例如,在图2-62中,7号结点到U集合中的最邻近点是2,closest[7]=2,如图2-63所示。7号结点到最邻近点2的边值为1,即边(2,7)的权值,记为lowcost[7]=1,如图2-64所示。
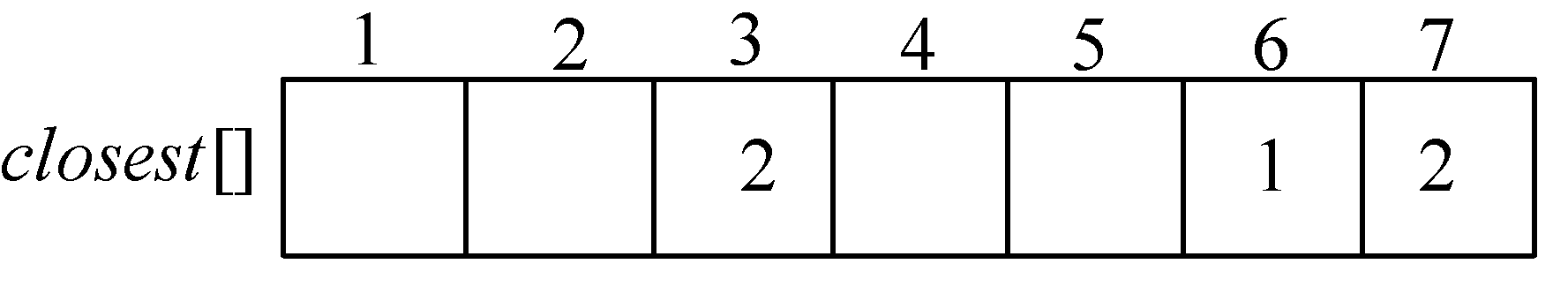

只需要在V−U集合中找lowcost[]值最小的顶点即可。
步骤2:初始化。令集合U={u0},u0∈V,并初始化数组closest[]、lowcost[]和s[]。
步骤3:在V−U集合中找lowcost值最小的顶点t,即lowcost[t]=min{lowcost[j]|j∈V−U},满足该公式的顶点t就是集合V−U中连接集合U的最邻近点。
步骤4:将顶点t加入集合U。
步骤5:如果集合V−U,算法结束,否则,转步骤6。
步骤6:对集合V−U中的所有顶点j,更新其lowcost[]和closest[]。更新公式:if(C[t] [j]<lowcost [j] ) { lowcost [j]= C [t] [j]; closest [j] = t; },转步骤3。
按照上述步骤,最终可以得到一棵权值之和最小的生成树。
2.7.3 完美图解
设G =(V,E)是无向连通带权图,如图2-65所示。
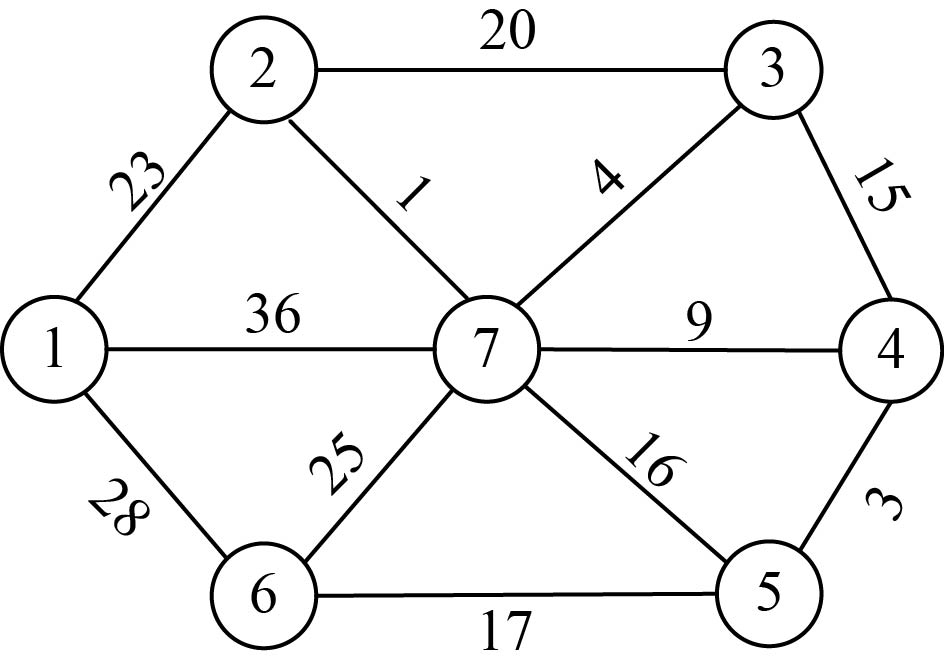
(1)数据结构
设置地图的带权邻接矩阵为C[][],即如果从顶点i到顶点j有边,就让C[i][j]=<i,j>的权值,否则C[i][j]=∞(无穷大),如图2-66所示。

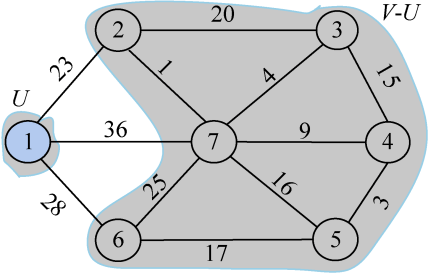
(2)初始化
假设u0=1;令集合U={1},V−U={2,3,4,5,6,7},TE={},s[1]=true,初始化数组closest[]:除了1号结点外其余结点均为1,表示V−U中的顶点到集合U的最临近点均为1,如图2-67所示。lowcost[]:1号结点到V−U中的顶点的边值,即读取邻接矩阵第1行,如图2-68所示。


初始化后如图2-69所示。
(3)找最小
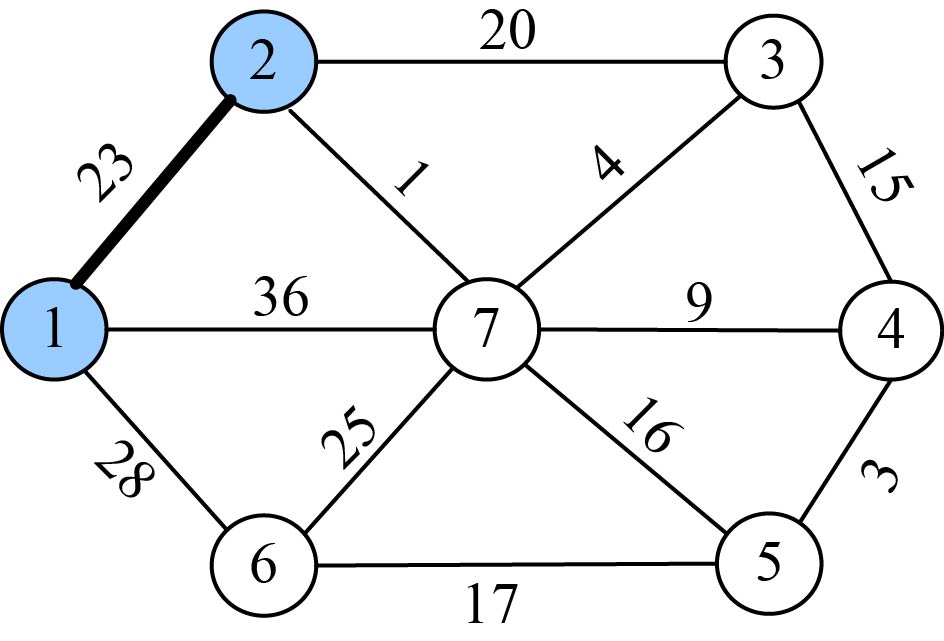
在集合V−U={2,3,4,5,6,7}中,依照贪心策略寻找V−U集合中lowcost最小的顶点t,如图2-70所示。

找到最小值为23,对应的结点t=2。
选中的边和结点如图2-71所示。
(4)加入U战队
将顶点t加入集合U={1,2},同时更新V−U={3,4,5,6,7}。
(5)更新
刚刚找到了到U集合的最邻近点t = 2,那么对t在集合V−U中每一个邻接点j,都可以借助t更新。我们从图或邻接矩阵可以看出,2号结点的邻接点是3和7号结点:
C[2][3]=20<lowcost[3]=∞,更新最邻近距离lowcost[3]=20,最邻近点closest[3]=2;
C[2][7]=1<lowcost[7]=36,更新最邻近距离lowcost[7]=1,最邻近点closest[7]=2;
更新后的closest[j]和lowcost[j]数组如图2-72和图2-73所示。


更新后如图2-74所示。
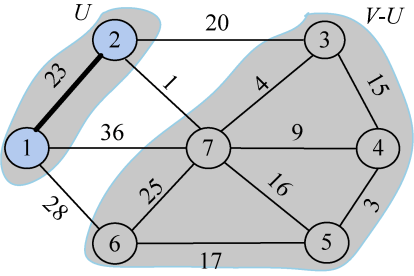
closest[j]和lowcost[j]分别表示V−U集合中顶点j到U集合的最邻近顶点和最邻近距离。3号顶点到U集合的最邻近点为2,最邻近距离为20;4、5号顶点到U集合的最邻近点仍为初始化状态1,最邻近距离为∞;6号顶点到U集合的最邻近点为1,最邻近距离为26;7号顶点到U集合的最邻近点为2,最邻近距离为1。
(6)找最小
在集合V−U={3,4,5,6,7}中,依照贪心策略寻找V−U集合中lowcost最小的顶点t,如图2-75所示。
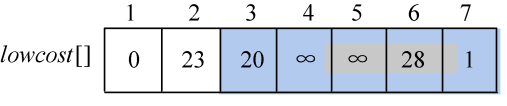
找到最小值为1,对应的结点t=7。
选中的边和结点如图2-76所示。
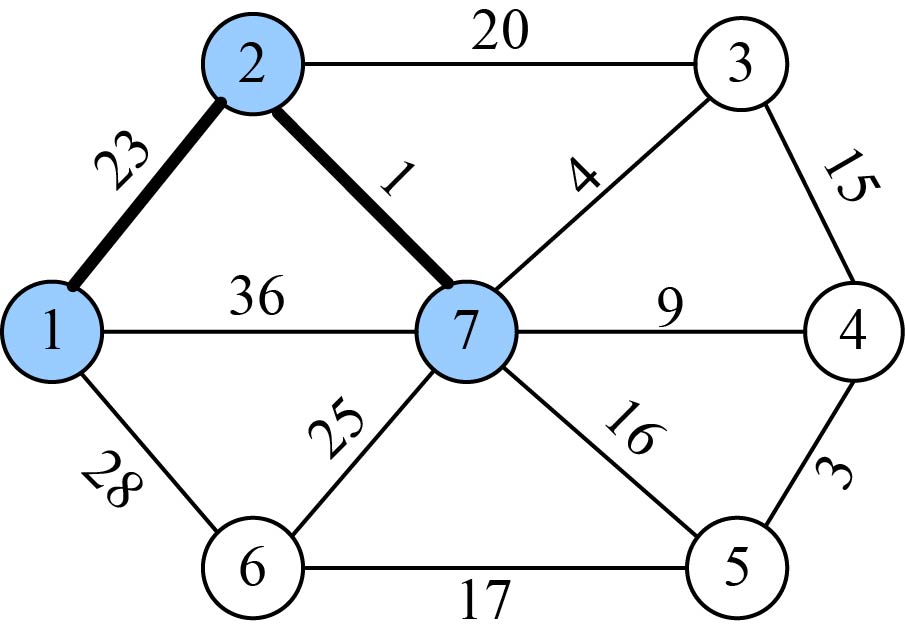
(7)加入U战队
将顶点t加入集合U={1,2,7},同时更新V−U={3,4,5,6}。
(8)更新
刚刚找到了到U集合的最邻近点t =7,那么对t在集合V−U中每一个邻接点j,都可以借t更新。我们从图或邻接矩阵可以看出,7号结点在集合V−U中的邻接点是3、4、5、6结点:
C[7][3]=4<lowcost[3]=20,更新最邻近距离lowcost[3]=4,最邻近点closest[3]=7;
C[7][4]=9<lowcost[4]=∞,更新最邻近距离lowcost[4]=9,最邻近点closest[4]=7;
C[7][5]=16<lowcost[5]=∞,更新最邻近距离lowcost[5]=16,最邻近点closest[5]=7;
C[7][6]=25<lowcost[6]=28,更新最邻近距离lowcost[6]=25,最邻近点closest[6]=7;
更新后的closest[j]和lowcost[j]数组如图2-77和图2-78所示。


更新后如图2-79所示。
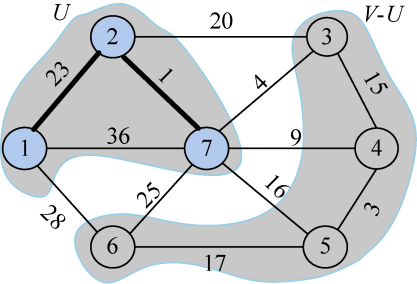
closest[j]和lowcost[j]分别表示V−U集合中顶点j到U集合的最邻近顶点和最邻近距离。3号顶点到U集合的最邻近点为7,最邻近距离为4;4号顶点到U集合的最邻近点为7,最邻近距离为9;5号顶点到U集合的最邻近点为7,最邻近距离为16;6号顶点到U集合的最邻近点为7,最邻近距离为25。
(9)找最小
在集合V−U={3,4,5,6}中,依照贪心策略寻找V−U集合中lowcost最小的顶点t,如图2-80所示。

找到最小值为4,对应的结点t=3。
选中的边和结点如图2-81所示。
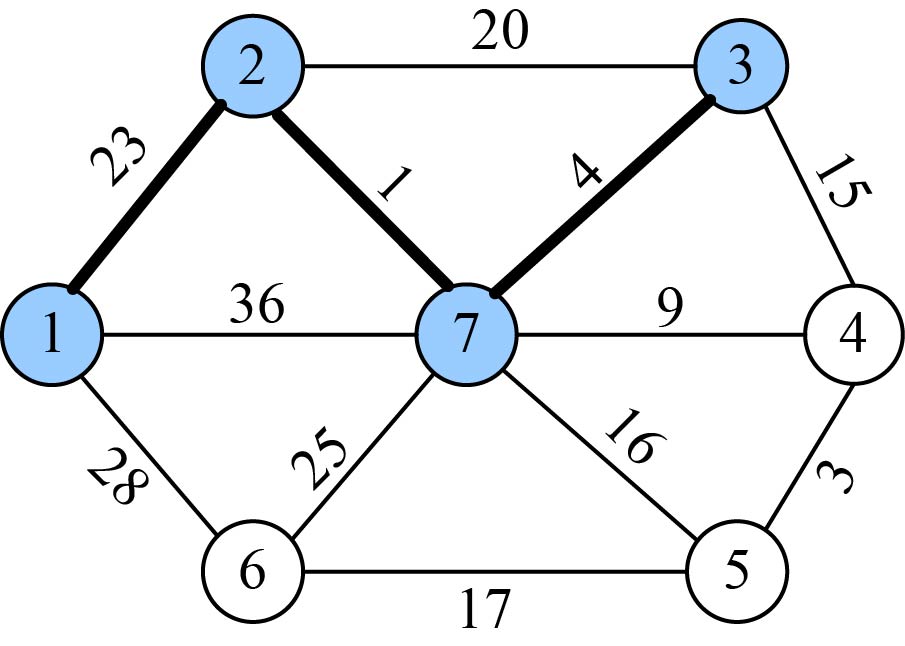
(10)加入U战队
将顶点t加入集合U ={1,2,3,7},同时更新V−U={4,5,6}。
(11)更新
刚刚找到了到U集合的最邻近点t =3,那么对t在集合V−U中每一个邻接点j,都可以借助t更新。我们从图或邻接矩阵可以看出,3号结点在集合V−U中的邻接点是4号结点:
C[3][4]=15>lowcost[4]=9,不更新。
closest[j]和lowcost[j]数组不改变。
更新后如图2-82所示。
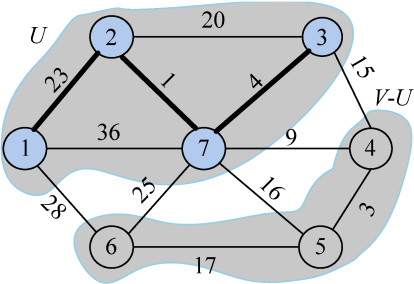
closest[j]和lowcost[j]分别表示V−U集合中顶点j到U集合的最邻近顶点和最邻近距离。4号顶点到U集合的最邻近点为7,最邻近距离为9;5号顶点到U集合的最邻近点为7,最邻近距离为16;6号顶点到U集合的最邻近点为7,最邻近距离为25。
(12)找最小
在集合V−U={4,5,6}中,依照贪心策略寻找V−U集合中lowcost最小的顶点t,如图2-83所示。

找到最小值为9,对应的结点t=4。
选中的边和结点如图2-84所示。
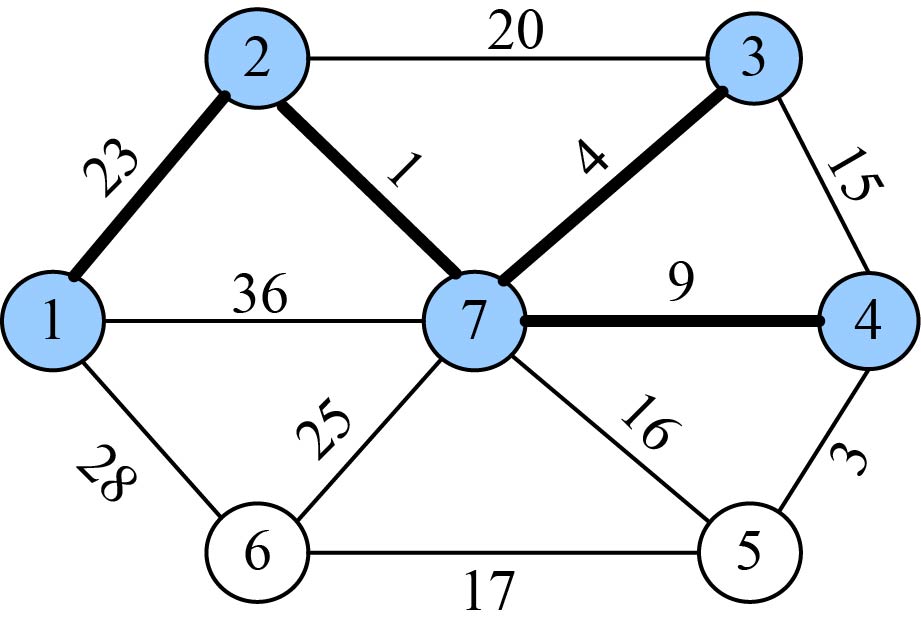
(13)加入U战队
将顶点t加入集合U ={1,2,3,4,7},同时更新V−U={5,6}。
(14)更新
刚刚找到了到U集合的最邻近点t =4,那么对t在集合V−U中每一个邻接点j,都可以借助t更新。我们从图或邻接矩阵可以看出,4号结点在集合V−U中的邻接点是5号结点:
C[4][5]=3<lowcost[5]=16,更新最邻近距离lowcost[5]=3,最邻近点closest[5]=4;
更新后的closest[j]和lowcost[j]数组如图2-85和图2-86所示。


更新后如图2-87所示。
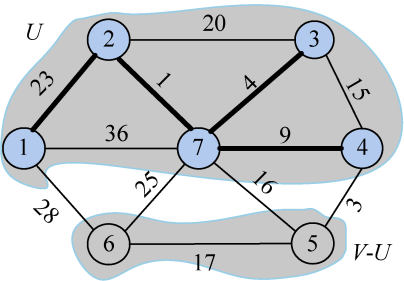
closest[j]和lowcost[j]分别表示V−U集合中顶点j到U集合的最邻近顶点和最邻近距离。5号顶点到U集合的最邻近点为4,最邻近距离为3;6号顶点到U集合的最邻近点为7,最邻近距离为25。
(15)找最小
在集合V−U={5,6}中,依照贪心策略寻找V−U集合中lowcost最小的顶点t,如图2-88所示。

找到最小值为3,对应的结点t=5。
选中的边和结点如图2-89所示。
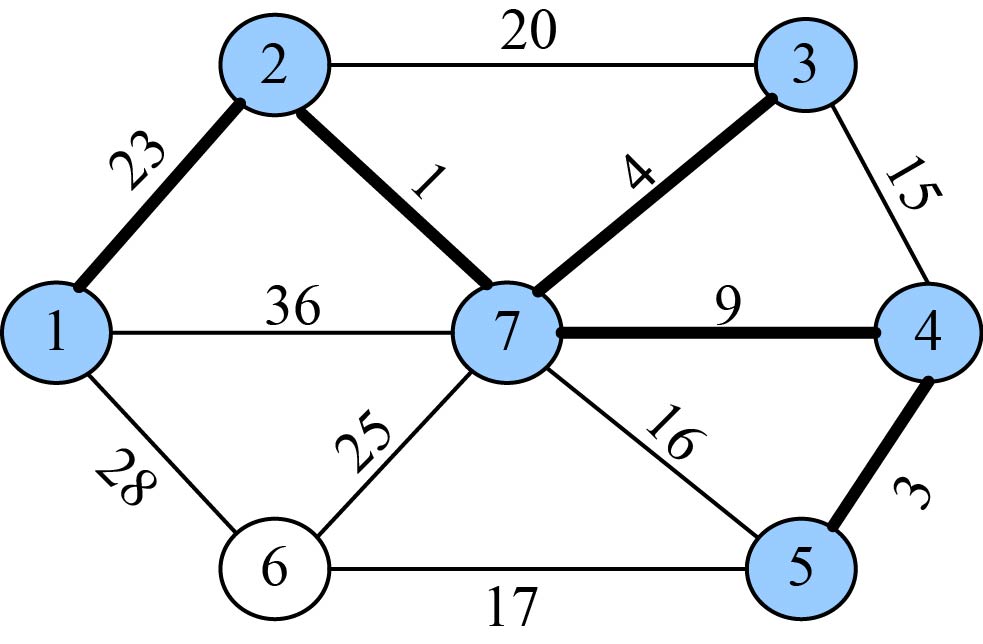
(16)加入U战队
将顶点t加入集合U={1,2,3,4,5,7},同时更新V−U={6}。
(17)更新
刚刚找到了到U集合的最邻近点t =5,那么对t在集合V−U中每一个邻接点j,都可以借助t更新。我们从图或邻接矩阵可以看出,5号结点在集合V−U中的邻接点是6号结点:
C[5][6]=17<lowcost[6]=25,更新最邻近距离lowcost[6]=17,最邻近点closest[6]=5;
更新后的closest[j]和lowcost[j]数组如图2-90和图2-91所示。


更新后如图2-92所示。
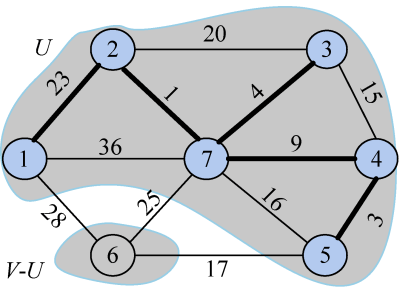
closest[j]和lowcost[j]分别表示V−U集合中顶点j到U集合的最邻近顶点和最邻近距离。6号顶点到U集合的最邻近点为5,最邻近距离为17。
(18)找最小
在集合V−U={6}中,依照贪心策略寻找V−U集合中lowcost最小的顶点t,如图2-93所示。

找到最小值为17,对应的结点t=6。
选中的边和结点如图2-94所示。
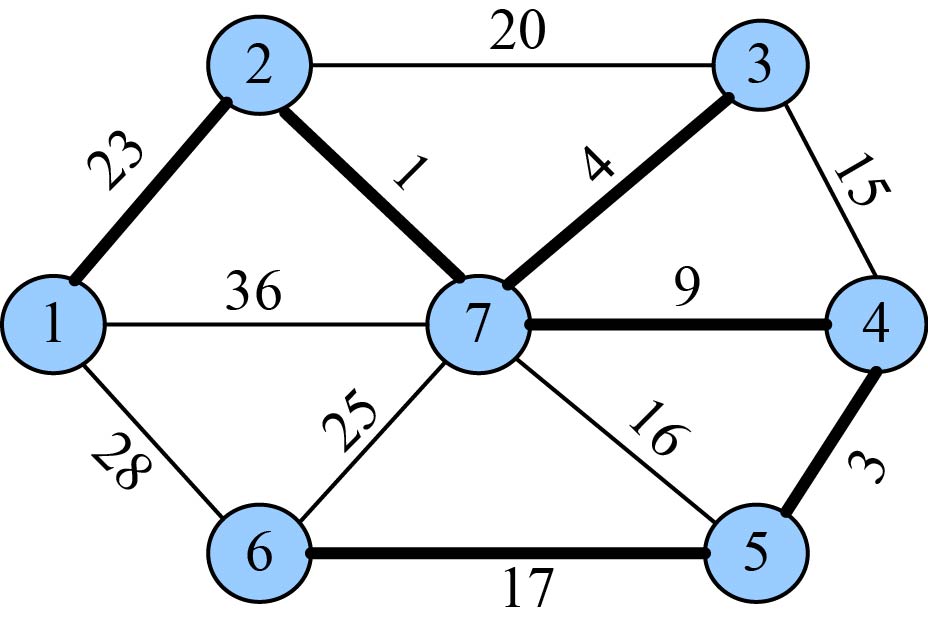
(19)加入U战队
将顶点t加入集合U ={1,2,3,4,5,6,7},同时更新V−U={}。
(20)更新
刚刚找到了到U集合的最邻近点t =6,那么对t在集合V−U中每一个邻接点j,都可以借t更新。我们从图2-94可以看出,6号结点在集合V−U中无邻接点,因为V−U={}。
closest[j]和lowcost[j]数组如图2-95和图2-96所示。


得到的最小生成树如图2-97所示。
最小生成树权值之和为57,即把lowcost数组中的值全部加起来。
2.7.4 伪代码详解
(1)初始化。s[1]=true,初始化数组closest,除了u0外其余顶点最邻近点均为u0,表示V−U中的顶点到集合U的最临近点均为u0;初始代数组lowcost,u0到V−U中的顶点的边值,无边相连则为∞(无穷大)。
1 | s[u0] = true; //初始时,集合中U只有一个元素,即顶点u0 |
(2)在集合V−U中寻找距离集合U最近的顶点t。
1 | int temp = INF; |
(3)更新lowcost和closest数组。
1 | s[t] = true; //否则,讲t加入集合U |
2.7.5 实战演练
1 | //program 2-7 |
算法实现和测试
(1)运行环境
Code::Blocks
(2)输入
1 | 输入结点数n和边数m: |
(3)输出
1 | 数组lowcost的内容为: |
2.7.6 算法解析
(1)时间复杂度:在Prim(int n,int u0,int c[N][N])算法中,一共有4个for语句,第①个for语句的执行次数为n,第②个for语句里面嵌套了两个for语句③、④,它们的执行次数均为n,对算法的运行时间贡献最大。当外层循环标号为1时,③、④语句在内层循环的控制下均执行n次,外层循环②从1~n。因此,该语句的执行次数为n*n=n²,算法的时间复杂度为O(n²)。
(2)空间复杂度:算法所需要的辅助空间包含i、j、lowcost和closest,则算法的空间复杂度是O(n)。
2.7.7 算法优化拓展
该算法可以从两个方面优化:
(1)for语句③找lowcost最小值时使用优先队列,每次出队一个最小值,时间复杂度为logn,执行n次,总时间复杂度为O( n logn)。
(2)for语句④更新lowcost和closest数据时,如果图采用邻接表存储,每次只检查t的邻接边,不用从1~n检查,检查更新的次数为E(边数),每次更新数据入队,入队的时间复杂度为logn,这样更新的时间复杂度为O( Elogn)。
1.算法设计
构造最小生成树还有一种算法,Kurskal算法:设G=(V,E)是无向连通带权图,V={1,2,…,n};设最小生成树T=(V,TE),该树的初始状态为只有n个顶点而无边的非连通图T=(V,{}),Kruskal算法将这n个顶点看成是n个孤立的连通分支。它首先将所有的边按权值从小到大排序,然后只要T中选中的边数不到n−1,就做如下的贪心选择:在边集E中选取权值最小的边(i,j),如果将边(i,j)加入集合TE中不产生回路(圈),则将边(i,j)加入边集TE中,即用边(i,j)将这两个连通分支合并连接成一个连通分支;否则继续选择下一条最短边。把边(i,j)从集合E中删去。继续上面的贪心选择,直到T中所有顶点都在同一个连通分支上为止。此时,选取到的n−1条边恰好构成G的一棵最小生成树T。
那么,怎样判断加入某条边后图T会不会出现回路呢?
该算法对于手工计算十分方便,因为用肉眼可以很容易看到挑选哪些边能够避免构成回路(避圈法),但使用计算机程序来实现时,还需要一种机制来进行判断。Kruskal算法用了一个非常聪明的方法,就是运用集合避圈:如果所选择加入的边的起点和终点都在T的集合中,那么就可以断定一定会形成回路(圈)。其实就是我们前面提到的“避圈法”:边的两个结点不能属于同一集合。
步骤1:初始化。将图G的边集E中的所有边按权值从小到大排序,边集TE={ },把每个顶点都初始化为一个孤立的分支,即一个顶点对应一个集合。
步骤2:在E中寻找权值最小的边(i,j)。
步骤3:如果顶点i和j位于两个不同连通分支,则将边(i,j)加入边集TE,并执行合并操作,将两个连通分支进行合并。
步骤4:将边(i,j)从集合E中删去,即E=E−{(i,j)}。
步骤 5:如果选取边数小于n−1,转步骤2;否则,算法结束,生成最小生成树T。
2.完美图解
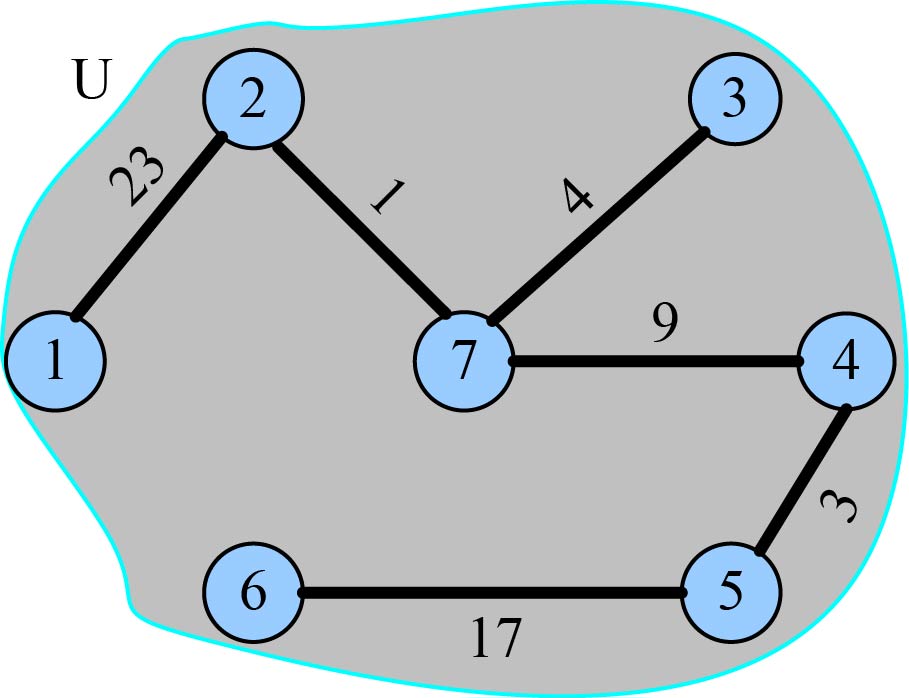
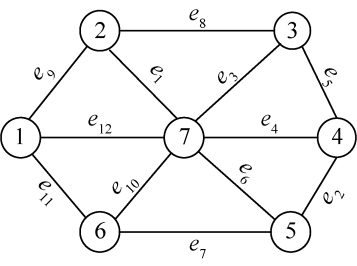
设G =(V,E)是无向连通带权图,如图2-98所示。
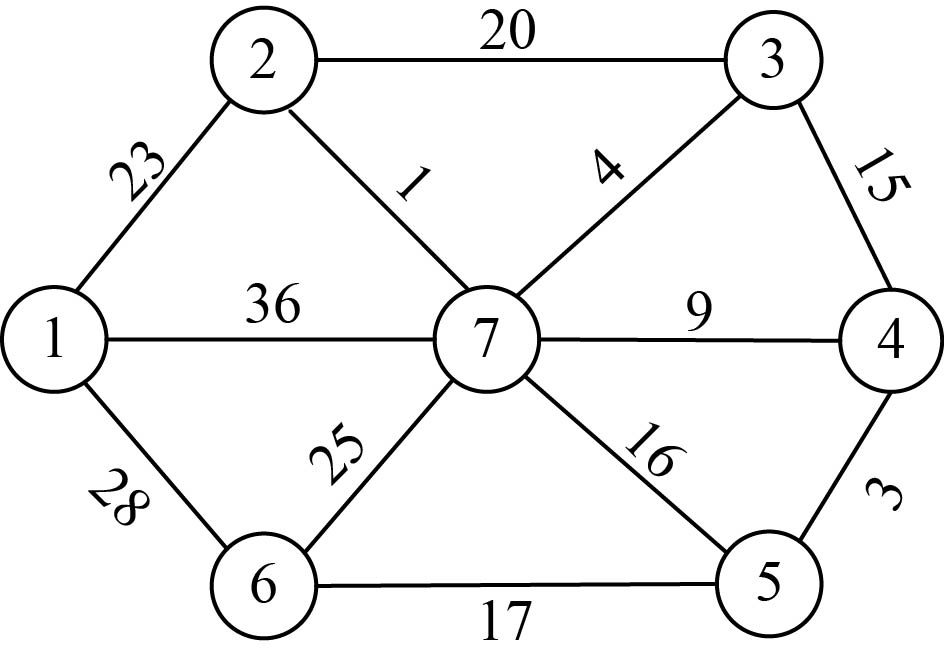
(1)初始化
将图G的边集E中的所有边按权值从小到大排序,如图2-99所示。
边集初始化为空集,TE={ },把每个结点都初始化为一个孤立的分支,即一个顶点对应一个集合,集合号为该结点的序号,如图2-100所示。
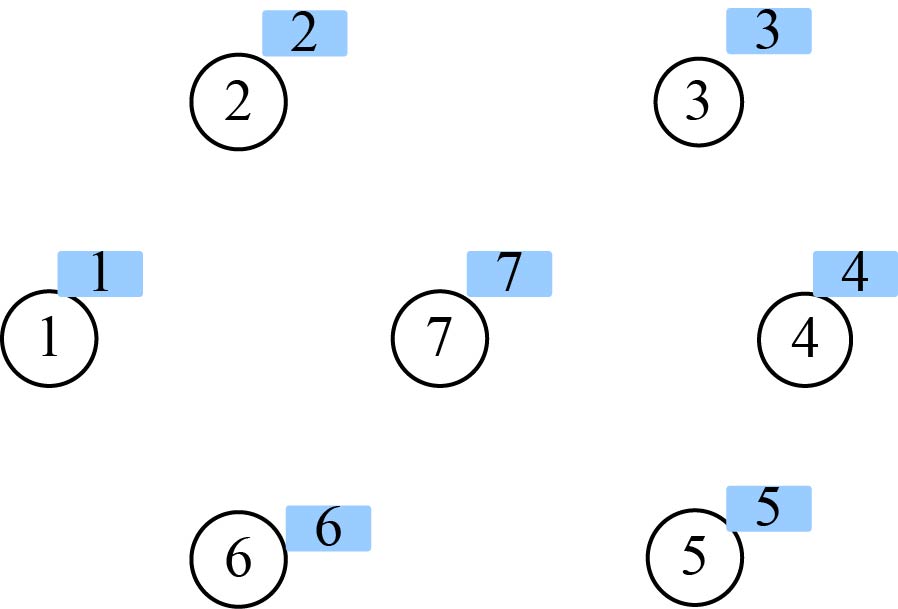
(2)找最小
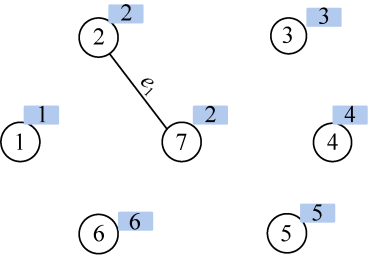
在E中寻找权值最小的边e1(2,7),边值为1。
(3)合并
结点2和结点7的集合号不同,即属于两个不同连通分支,则将边(2,7)加入边集TE,执行合并操作(将两个连通分支所有结点合并为一个集合);假设把小的集合号赋值给大的集合号,那么7号结点的集合号也改为2,如图2-101所示。
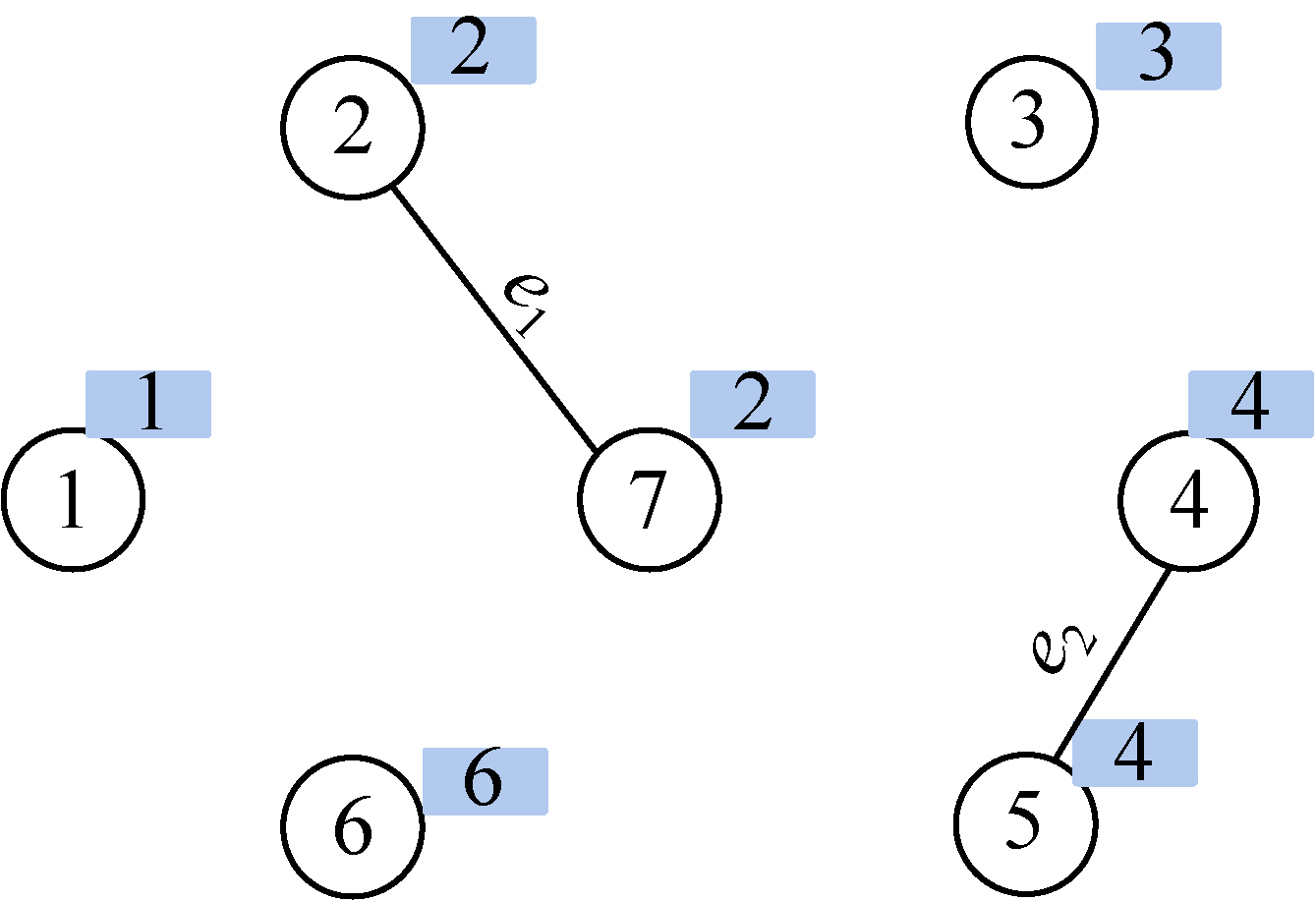
(4)找最小
在E中寻找权值最小的边e2(4,5),边值为3。
(5)合并
结点4和结点5集合号不同,即属于两个不同连通分支,则将边(4,5)加入边集TE,执行合并操作将两个连通分支所有结点合并为一个集合;假设我们把小的集合号赋值给大的集合号,那么5号结点的集合号也改为4,如图2-102所示。
(6)找最小
在E中寻找权值最小的边e3(3,7),边值为4。
(7)合并
结点3和结点7集合号不同,即属于两个不同连通分支,则将边(3,7)加入边集TE,执行合并操作将两个连通分支所有结点合并为一个集合;假设我们把小的集合号赋值给大的集合号,那么3号结点的集合号也改为2,如图2-103所示。
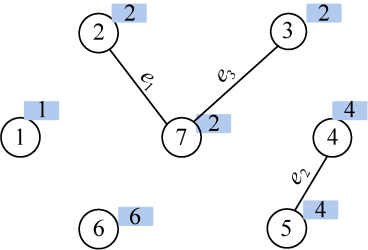
(8)找最小
在E中寻找权值最小的边e4(4,7),边值为9。
(9)合并
结点4和结点7集合号不同,即属于两个不同连通分支,则将边(4,7)加入边集TE,执行合并操作将两个连通分支所有结点合并为一个集合;假设我们把小的集合号赋值给大的集合号,那么4、5号结点的集合号都改为2,如图2-104所示。
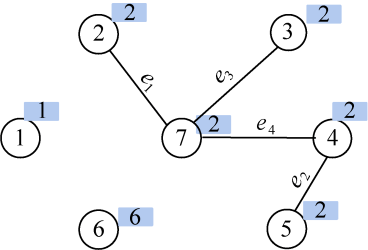
(10)找最小
在E中寻找权值最小的边e5(3,4),边值为15。
(11)合并
结点3和结点4集合号相同,属于同一连通分支,不能选择,否则会形成回路。
(12)找最小
在E中寻找权值最小的边e6(5,7),边值为16。
(13)合并
结点5和结点7集合号相同,属于同一连通分支,不能选择,否则会形成回路。
(14)找最小
在E中寻找权值最小的边e7(5,6),边值为17。
(15)合并
结点5和结点6集合号不同,即属于两个不同连通分支,则将边(5,6)加入边集TE,执行合并操作将两个连通分支所有结点合并为一个集合;假设我们把小的集合号赋值给大的集合号,那么6号结点的集合号都改为2,如图2-105所示。
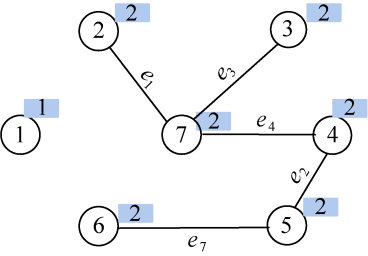
(16)找最小
在E中寻找权值最小的边e8(2,3),边值为20。
(17)合并
结点2和结点3集合号相同,属于同一连通分支,不能选择,否则会形成回路。
(18)找最小
在E中寻找权值最小的边e9(1,2),边值为23。
(19)合并
结点1和结点2集合号不同,即属于两个不同连通分支,则将边(1,2)加入边集TE,执行合并操作将两个连通分支所有结点合并为一个集合;假设我们把小的集合号赋值给大的集合号,那么2、3、4、5、6、7号结点的集合号都改为1,如图2-106所示。
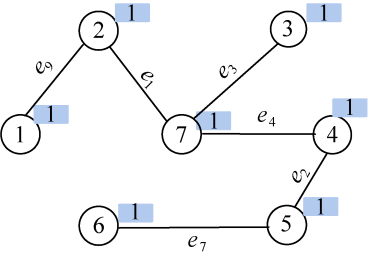
(20)选中的各边和所有的顶点就是最小生成树,各边权值之和就是最小生成树的代价。
3.伪码详解
(1)数据结构
1 | int nodeset[N];//集合号数组 |
(2)初始化
1 | void Init(int n) |
(3)对边进行排序
1 | bool comp(Edge x, Edge y) |
(4)合并集合
1 | int Merge(int a, int b) |
4.实战演练
1 | //program 2-8 |
5.算法复杂度分析
(1)时间复杂度:算法中,需要对边进行排序,若使用快速排序,执行次数为eloge,算法的时间复杂度为O(eloge)。而合并集合需要n−1次合并,每次为O(n),合并集合的时间复杂度为O(n2)。
(2)空间复杂度:算法所需要的辅助空间包含集合号数组 nodeset[n],则算法的空间复杂度是O(n)。
6.算法优化拓展
该算法合并集合的时间复杂度为O(n2),我们可以用并查集(见附录E)的思想优化,使合并集合的时间复杂度降为O(e*logn),优化后的程序如下。
1 | //program 2-9 |
算法实现和测试
(1)运行环境
Code::Blocks
(2)输入
1 | 输入结点数n和边数m: |
(3)输出
1 | 最小的花费是:57 |
7.两种算法的比较
(1)从算法的思想可以看出,如果图G中的边数较小时,可以采用Kruskal算法,因为Kruskal算法每次查找最短的边;边数较多可以用Prim算法,因为它是每次加一个结点。可见,Kruskal算法适用于稀疏图,而Prim算法适用于稠密图。
(2)从时间上讲,Prim算法的时间复杂度为O(n2),Kruskal算法的时间复杂度为O(eloge)。
(3)从空间上讲,显然在Prim算法中,只需要很小的空间就可以完成算法,因为每一次都是从V−U集合出发进行扫描的,只扫描与当前结点集到U集合的最小边。但在Kruskal算法中,需要对所有的边进行排序,对于大型图而言,Kruskal算法需要占用比Prim算法大得多的空间。